Fast RCNN论文理解
Fast RCNN论文理解
在Fast RCNN提出前,目标检测领域效果较好的算法是RCNN和SPPnet,因此本文主要将Fast RCNN的改进与这两种算法进行对比。
RCNN和SPPnet的缺点
RCNN的缺点
训练是多阶段的
- 首先,在候选区域上微调ConvNet
- 然后,对ConvNet产生的特征训练SVMs分类器,用来代替微调的CNN网络学到的softmax分类器
- 最后,学习边界框回归网络
训练耗费时间和空间
- 为了训练SVM分类器和边界框回归网络,从ConvNet抽取到的候选区域的特征要先被写入磁盘
- 耗时:RCNN对每个候选区域都执行ConvNet前向传播来提取特征,没有共享计算
测试很慢
- 每张测试图片要先获取2000个候选区域,再对每个区域抽取特征,耗时很长
SPPnet的缺点
SPPnet对RCNN的改进
SPPnet对RCNN进行了改进,引入了一个空间金字塔池化层(SPP layer),这个层的本质是:通过采用动态的池化核尺寸,来限制最终特征输出尺寸的最大池化层(max pooling layer)。从而使网络借助该层可以把不同大小的候选区域特征图转换成特定大小的输出。
因此该网络的运行流程大致如下:
输入整张图片进行前向传播,计算一个卷积特征图=>从这个共享特征图抠出每个候选区域的特征图=>通过SPP layer把不同大小的候选区域特征图转换成特定大小的输出=>对特征向量进行分类。
这种做法只需要对整张图片做一次前向传播,得到整张图片的特征图,再从中抠出不同候选区域的特征图即可,不用像RCNN一样对2000张候选区域图像做2000次前向传播,实现了通过共享计算来加速,解决了RCNN预测时速度慢的问题
SPPnet的缺点
- 训练是多阶段的:抽取特征==》微调网络==》训练SVMs分类器==》训练边界框回归
- 耗费时间和空间:因为要额外训练SVMs分类器和边界框回归网络,所以CNN得出的特征仍然要被写入磁盘
- SPPnet的微调算法部分不能更新卷积层的参数,限制了深层网络的精度
主要贡献
- 精度更高(比RCNN、SPPnet)
- 训练使用多任务损失函数(multi-task loss)实现单阶段的训练
- 训练可以更新所有的网络层
- 不需要磁盘进行特征缓存
模型结构
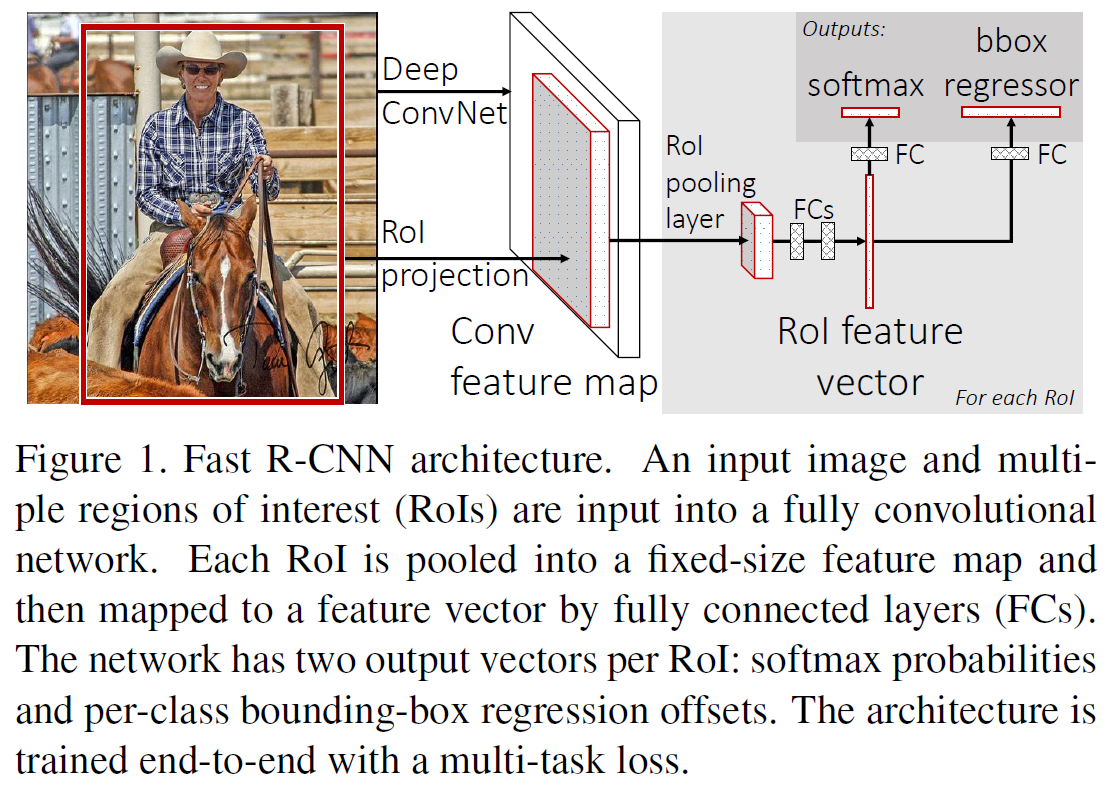
总体流程
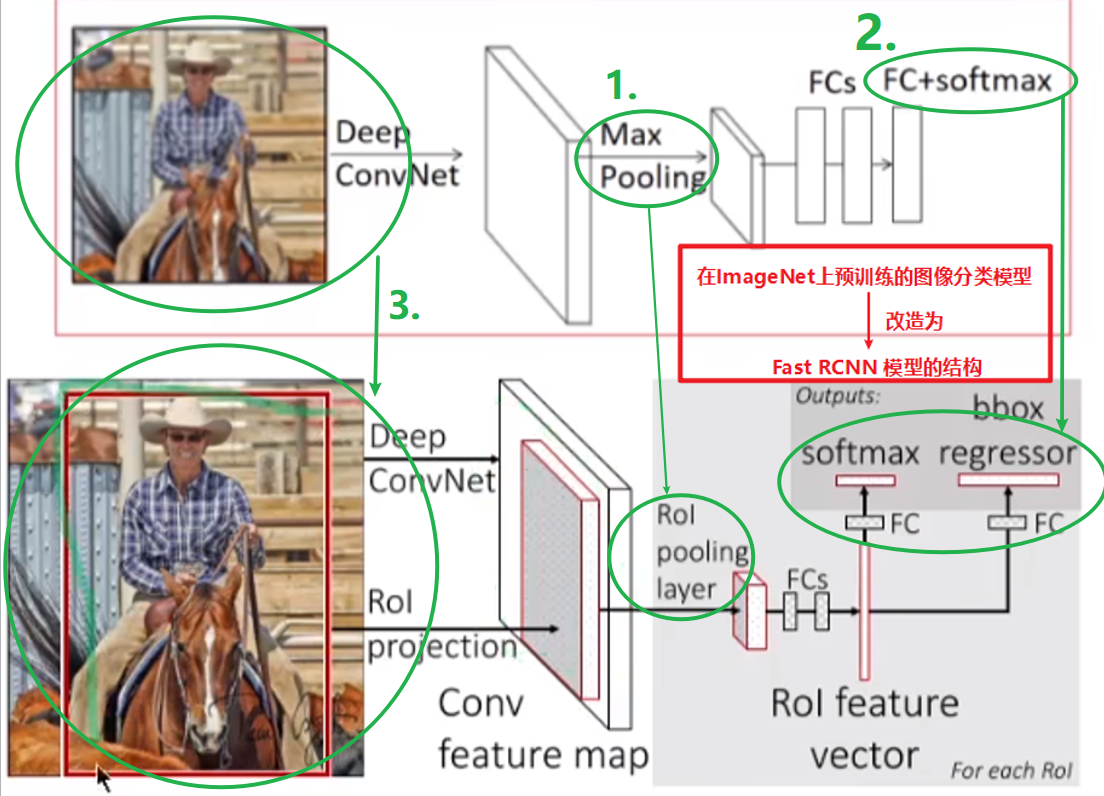
输入一整张图片和一套候选区域(也叫ROIs)=>Deep ConvNet(卷积+池化)得到整体的特征图=>根据候选区域在原图中的位置,使用ROI投影,获取到候选区域的特征图=>针对每个候选区域,用ROI池化层把尺寸不固定的候选区域特征图转换成特定尺寸的特征图(如7 x 7)=>接上2个全连接层,得到每个候选区域的特征向量=>再接上两个并列的全连接层,获得两个输出:
- 利用softmax预测类别(对K+1个类别)
- 产生每个类别对应的边界框坐标((K+1)*4)
与SPPnet的区别
- SPPnet在ConvNet之后接上了SPP layer(空间金字塔池化层),用来把不同尺寸的候选区域特征图转换为特定大小的输出;而Fast RCNN在ConvNet之后接上了ROI pooling layer(ROI池化层),用于把不同尺寸的候选区域特征图转换成特定尺寸的特征图
- SPPnet在提取到图像的CNN特征后,又额外训练SVM进行分类和回归;而Fast RCNN就是直接接了两个并行的全连接层做分类和回归
组成部分及实现步骤
ROI池化层
用最大池化把感兴趣区域的特征转换成特定大小的特征图(如7 x 7),是spatial pyramid pooling layer只有一个金字塔层时的特例
初始化Fast RCNN
从在ImageNet上预训练好的图像分类模型(AlexNet)上初始化一个Fast RCNN,改造步骤为;
(1)首先,把Conv Net之后最后一层的最大池化层替换为一个ROI池化层
(2)其次,网络的最后一个全连接层和softmax层替换为两个并行的全连接层(一个分支用来预测K+1个类别,一个分支用来预测边界框回归)
(3)最后,网络要接受两个数据输入:a list of images和 a list of ROIs in those images
微调模型
即:通过反向传播来训练整个网络的权重
(1)为什么SPPnet不能更新空间金字塔池化层前的权重?
根本原因:当训练样本(ROIs)来自于不同的图片时,通过空间金字塔池化层(SPP layer)的反向传播是无效的。(至于为啥无效,没看懂解释)
(2)Fast RCNN是怎么有效训练的?(通过反向传播来训练整个网络的权重)
- mini-batch 分层采样:SGD的mini-batches是被分层采样的,先采样N个图片,然后从每张图片中采样R/N个ROIs。这样,来自同一张图片的ROIs就能在前向传播和后向传播中共享计算和内存。论文中取N=2,R=128。即每次采样2张图片,从每张图片采样64个ROI。
- 精简训练过程:用一个微调阶段共同优化一个softmax分类器和边界框回归器
(3)multi-task loss
multi-task loss = 类别损失 + 框回归损失
- 类别损失
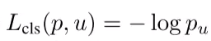
- 框回归损失

(4)mini-batch 分层采样
(5)通过ROI池化层反向传播
(6)SGD 超参数
目标的尺度不变性
(1)含义:如果有两个内容相同的目标,唯一区别是一个目标比较小,一个目标比较大,如果网络能将这两个目标都识别出来,说明网络具有较好的尺度不变性
(2)两种策略:
- 单尺度训练:每张图片都被处理成预定义好的图片尺寸来进行训练和预测。让网络来直接学会尺度不变性
- 多尺度训练:在训练期间,每一张图片都被随机采样成特定的尺度。这也是一种数据增强的手段
测试流程
接收输入(一张图片和这张图片中的一系列候选区域),输入网络就能预测出候选区域的类别和精确坐标
截断的奇异值分解
能够减少全连接层的参数,从而加速全连接层
实验设置
更换不同的CNN网络结构(AlexNet、VGG_CNN_M_1024、VGG16),对比实验结果(精度和测试时间)。
此外,还关注了一个问题:对于SPPnet中不太深的ConvNet,只微调全连接层就足以获得较好的精度,然而论文在这里假设:对于很深的网络,上述结论不成立。进而提出了一个问题:微调哪些层的效果更好?
实验结果是:微调卷积层精度高于只微调全连接层
模型的设计评估
多任务训练是否有效
多任务训练:指同时训练分类和边界框回归任务,共同调整一套参数
多阶段训练:指分类和边界框回归分成两个阶段进行训练,先训练分类,训练好后冻结参数,再额外训练一个边界框回归分支,也会利用第二个分支的回归结果
实验结果表明:多任务的训练结果比多阶段的要好
单尺度还是多尺度训练?
单尺度训练:把短边固定到600像素
多尺度训练:把短边固定到5种像素
结果:多尺度精度更高
是否需要更多训练数据
扩增2007数据集,精度会提高。不会出现传统模型出现的精度饱和的情况
SVM是不是比softmax好?
实验结果:Fast RCNN中,直接用softmax效果比好
候选区域是不是越多越好?
实验结果:候选区域越多,精度先提升后下降
参考资料:
https://www.bilibili.com/video/BV1y94y1Q7QJ/?spm_id_from=333.880.my_history.page.click&vd_source=66a72b15abe9693bd8b4f738f5a67ee7