Faster RCNN论文理解
Faster RCNN论文理解
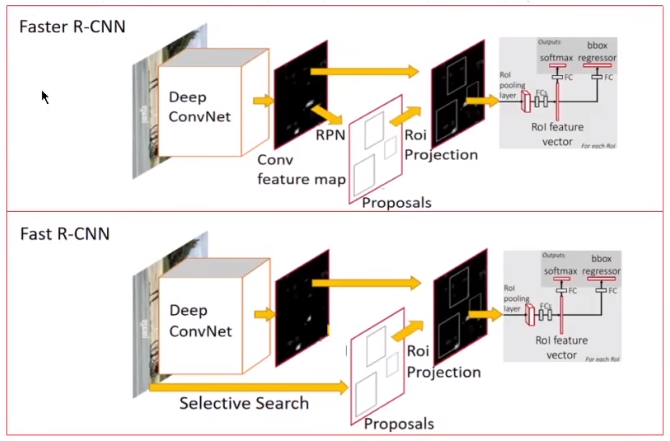
背景
基于候选区域的CNNs(RCNN、SPPnet、FastRCNN...)在目标检测领域取得了很好的效果,尤其是共享卷积特征及大地降低了计算代价,提高了训练和测试的速度。如果忽略产生候选区域(region proposals)的耗时,Fast RCNN输入一张图片和其候选区域后几乎可以实现实时检测。因此,现在检测系统的计算瓶颈主要在于产生候选区域的部分。Selective Search (SS)产生一张图片的2000个候选区域要耗时2s,EdgeBoxes则要耗时0.2s(两种方法都只有CPU实现)——太慢了!因此,本文提出利用deep ConvNet来产生候选区域。
主要贡献
- 用RPN代替selective、EdgeBoxes产生候选区域:RPN(Region Proposal Networks),能够同时预测边界框和对象性得分(objectness scores),并和Fast RCNN目标检测网络共享了卷积特征,实现了网络加速。
- 提出了一种“轮流”的训练模式来合并RPN和Fast RCNN
RPN(Region Proposal Networks)
网络结构
下图展示了RPN的总体结构示意图
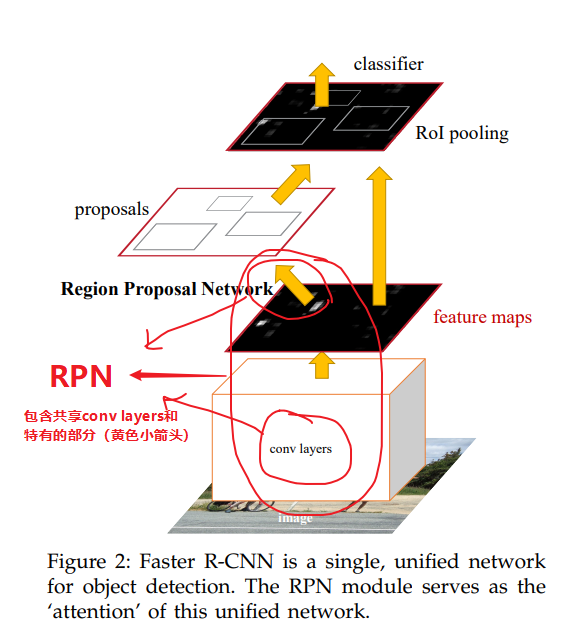
共享卷积层(conv layers)本文实验了ZF模型和VGG-16模型
输入:一张任意大小的图片
输出:一系列矩形候选区域及其对应的对象性得分(objectness score——object/not-object)
下图展示了"RPN特有部分"的结构示意图
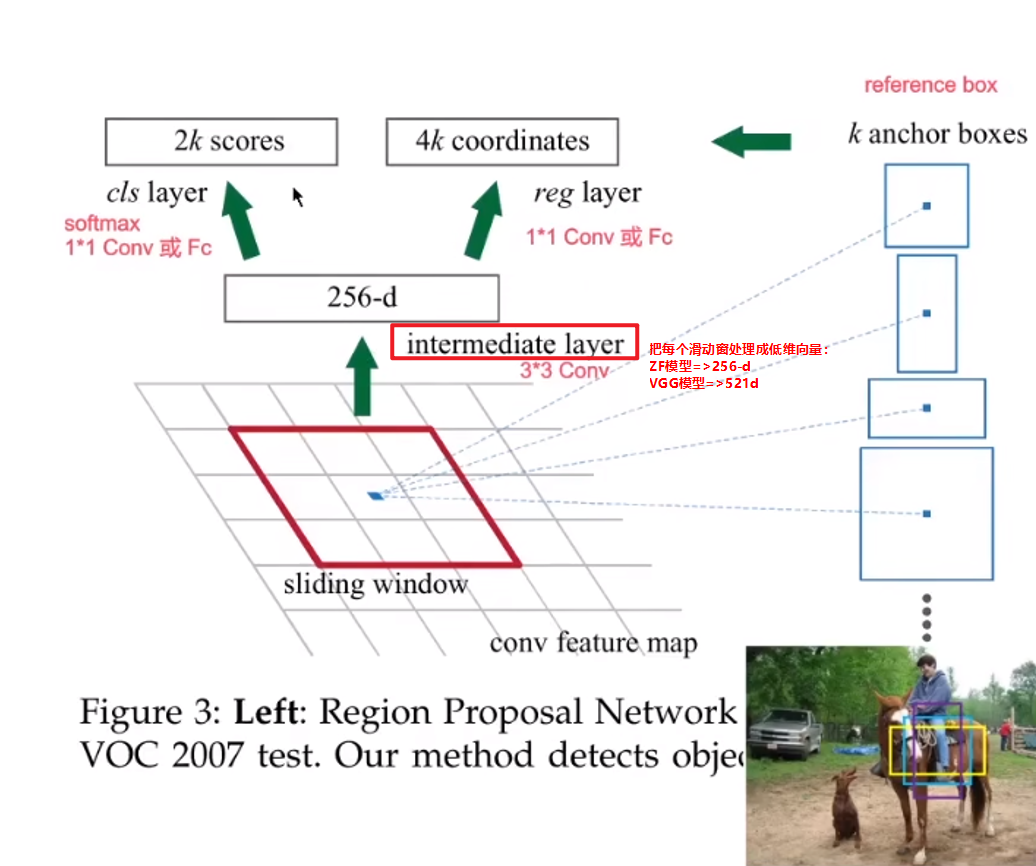
平移不变的参考框(Translation-Invariant Anchors)
用三种不同的尺度(scale)和长宽比(aspect ratio),在每个滑动窗口位置产生9种不同的参考框。
参考框和根据参考框计算候选区域的函数,二者都具有平移不变性
RPN损失函数
注意!!!这里是RPN的分类和回归网络两个分支的损失函数,不是Fast RCNN的损失函数
怎么判断预测的参考框是正样本还是负样本?
- 正样本:将参考框和所有的ground-truth计算IoU,与每个ground-truth有着最大IoU的参考框是正样本;将参考框和所有的ground-truth计算IoU,与任意ground-truth的IoU超过0.7的也是正样本
- 负样本:将参考框和所有的ground-truth计算IoU,与所有的ground-truth的IoU<0.3的是负样本
最小化Fast RCNN中的多任务损失函数(multi-task loss)
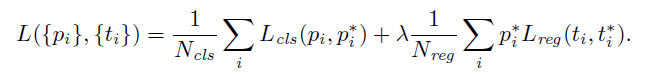
cls:识别参考框(anchor box)属于object or not-object;reg:将参考框(anchor box)回归到真实标注框(ground-truth box)
回归的实现方式有所改变:
- RCNN、Fast RCNN:将任意大小的候选区域池化后,执行边界框回归,回归权重被各尺寸的候选区域共享
- RPN:只在相同大小的特征图上进行回归,学习到k个不同的边界框回归器,它们之间的权重互不共享
训练RPN
以图片为中心采样(“image centric” sampling strategy):每个mini-batch来自于一张图片包含的正负样本。
实际做法:在一张图片上随机采样256个参考框,其中正负参考框占比接近1:1,用这些样本作为mini-batch,计算这个mini-batch的损失函数
Faster RCNN整体训练
Faster RCNN = RPN + Fast RCNN
如何共享
如何在RPN和Fast RCNN间共享卷积层?
思路1:轮流训练
step 1,训练RPN:用ImageNet上的预训练模型初始化RPN,并在端到端的区域建议任务上微调。
step 2,训练Fast RCNN:用step-1训练的RPN产生的候选区域 + ImageNet上的预训练模型从头训练一个Fast RCNN检测模型。到此为止,这两个网络还没有共享卷积层的特征。
step 3,用step-2得到的Fast RCNN检测网络的特征提取部分(Deep ConvNet)初始化RPN的训练,微调RPN特有的的层。此时,两个网络实现了共享卷积层。
step 4,固定共享卷积层,微调Fast RCNN的全连接层(特有的那些层)。到此为止,两个网络就共享了卷积层并形成了一个统一的网络。
下图展示了这一轮流训练过程 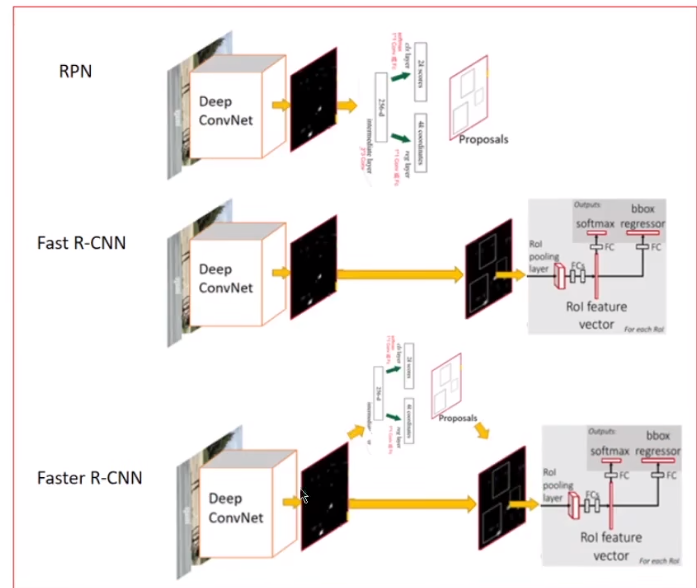
思路2:近似联合训练法
做法:训练初始就将RPN和Fast RCNN合并成一个网络,然后用同时进行反向传播来优化。
问题:无法求解坐标偏导数,因为Fast RCNN的损失函数反向传播也会传导到RPN回归出的坐标部分,但这种方法忽略了这部分
思路3:非近似联合训练法
利用ROI Warping实现了Fast RCNN尾部网络反向传播到坐标部分的问题
实现细节
RPN和Fast RCNN的训练和测试都使用了单尺度图片:缩放图片的短边为600px
参考框选取了3种尺度:1282,2562,512^2,3种长宽比:1:1,1:2,2:1=>不需要多尺寸特征、多尺寸滑动窗口来预测大区域
处理跨图片边界的参考框:
- 训练时忽略所有跨边界的参考框,因为如果不忽略跨边界的参考框,它们会在损失函数中引入很大很难纠正的错误模式,导致训练很难收敛。
- 测试时遇到跨图片边界的候选框,会保留其并裁剪其到图片边界

基于cls scores针对每一类别的候选区域应用非极大值抑制过滤,以减少冗余。当NMS的IoU的阈值设定为0.7时,每张图片最终会留下大约2k个候选区域,用这2k个候选区域训练Fast RCNN(测试时不一定需要使用2k个,实际使用了300个)
实验
数据集:PASCAL VOC 2007,5k trainval images,5k test images,超过20个对象类
评估指标:mAP
消融实验
困惑:在RPN和Fast RCNN之间共享卷积特征有什么作用?
1
2
3
4
5实验:在4-step的训练步骤的step-2后停下来,用2个分离的网络(RPN和Fast RCNN)完成获取候选区域和实现目标检测
实验结果:精度会下降
解释:说明step-2训练好的Fast RCNN网络的特征提取能力能更好地辅助RPN模块产生候选区域,提高了候选区域的质量困惑:只在测试时使用RPN产生的候选区域,对Fast RCNN检测网络有什么影响?(注意这里是Fast RCNN,Fast RCNN的训练还是采用selective-search产生的候选区域来实现的,而不是Faster RCNN,即这里RPN和Fast RCNN并没有共享卷积特征)
1
2
3
4
5
6
7
8实验1:
- 训练时:selective search产生2k个候选区域+ZF;
- 测试时:固定训练产生的检测器,采用RPN产生的候选区域。这时RPN并没有和此时的ZF共享特征。
实验结果:测试时用300个RPN产生的候选区域来代替selective-search,精度会下降
解释:精度损失是因为训练和测试时所用的候选区域(proposals)不一致,该结果为后续实验提供baseline1
2
3
4
5实验2:测试时用RPN产生的前100个候选区域代替前300个
实验结果:精度下降但下降不多
解释:说明排名靠前的RPN proposals很准确1
2
3实验3:测试时用前6k个RPN proposals(without NMS)产生的候选区域
实验结果:精度并没有比用300个RPN proposals(with NMS)更好,说明NMS并不损害检测时的mAP,测试时RPN的分类和回归输出分别有什么作用?
1
2
3
4
5实验1:测试时移除RPN的cls layer,然后从没有打分的region proposals随机采样N个proposals进行测试(关闭分类层会导致后续——不会进行NMS,因为NMS是针对每一类(object/not-object)的cls score来进行的,而此时没有分类了)
实验结果:N=1000时,精度几乎无影响;N=100是,精度大幅下降
解释:cls scores 考虑到了排名最高的proposals的准确性1
2
3
4
5实验2:测试时移除RPN的reg layer(移除reg layer的后续影响是——proposals变成了anchor boxes)
实验结果:精度下降
解释:高质量的候选区域(proposals)主要是因为位置回归,只有参考框不足以准确定位更强大的网络(VGG-16)对RPN产生的候选区域质量有什么影响
1
2
3
4
5实验:在上述实验(训练:selective-search + ZF,测试:利用ZF训练的RPN产生候选区域),改用VGG-16训练的RPN产生候选区域进行测试(注意这里RPN和目标检测网络都没有共享卷积特征)
结果:精度提高
解释:RPN+VGG-16产生的候选区域质量优于RPN+ZF(用ZF训练出来的RPN)
Recall-to-IoU
这个评估指标主要用于诊断(注意是诊断,不是评估)产生候选区域的方法的优劣
下图展示了不同候选区域算法(SS、EB、RPN+ZF、RPN+VGG)在不同IoU时的召回率
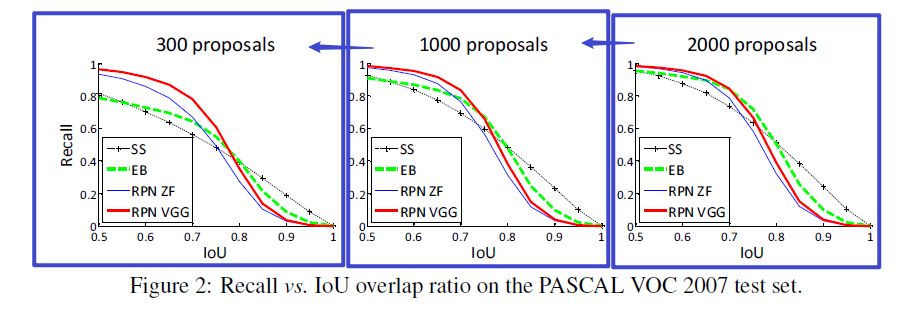
解释:
- 当proposals的数量下降的时候,RPN在各个IoU比率下的召回率都只是略微降低
- 当proposals的数量下降的时候,SS和EB方法在各个IoU比率下的召回率都显著降低
- 这就解释了为什么RPN只需要300个候选区域就能取得比较好的精度
一阶段检测vs两阶段检测
和OverFeat比较
参考资料:
https://www.bilibili.com/video/BV1GB4y1r7rM/?spm_id_from=333.880.my_history.page.click&vd_source=66a72b15abe9693bd8b4f738f5a67ee7