RCNN论文理解
RCNN
背景
过去主流的目标检测思路:输入一张图片=》获取一系列区域=》传统的特征提取方法(HOG特征)得到一组特征表示(x1,x2,...xn)=》输入预训练好的机器学习算法(SVM、决策树)进行分类
本文创新:用CNN代替传统的特征提取方法来提取图像特征
主要贡献
- 用CNN代替传统的特征提取方法来提取图像特征
- 迁移学习(模型微调):模型在大的源领域数据集上预训练后,再在特定目标领域的小数据集上微调,能够适应新任务的要求。——解决目标领域数据稀缺问题。
面临问题及解决思路
问题1:如何用CNN来定位目标?
问题
分类任务只需要确定类别;检测任务除了需要确定类别,还需要获得对象的检测边界框。CNN过去已经被证明可以用于分类任务,如何利用它来检测边界框呢?
解决思路
基于回归的定位策略:直接用CNN来回归边界框
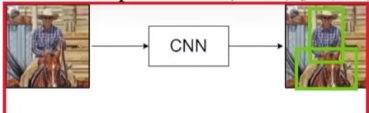
基于滑动窗口检测器的定位策略:在输入图片上用特定大小和比例的滑动窗口进行滑动,对于滑动到的区域用浅层的CNN进行检测,适用于人脸、行人这类特定比例的任务。(有人试了,效果不好)
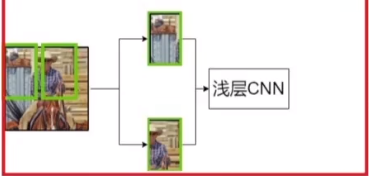
基于区域的定位策略(本文√):输入一张图片,用某种方法产生一定数量的候选区域(Region proposal),然后用一个深层的CNN提取特征,最后输入分类器种进行分类
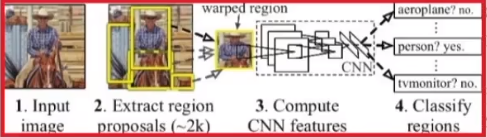
问题2:标注数据太少
问题
图像分类领域ImageNet数据集,标注数据丰富,而当时目标检测领域只有PASCAL VOC数据集,标注数据很少
解决思路
- 传统思路:无监督预训练+有监督微调
- 本文思路:迁移学习。在ImageNet大数据集上有监督预训练+在PASCAL VOC小数据集上微调
模型结构
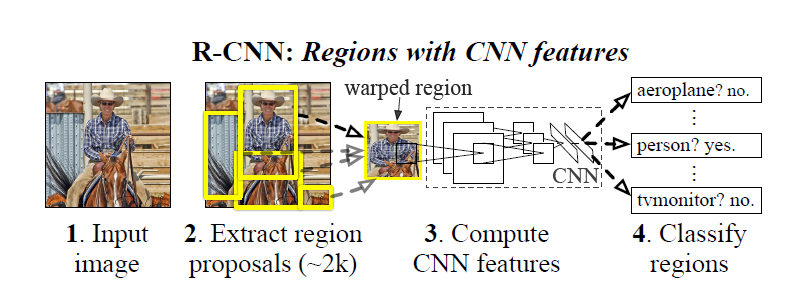
三个模块
产生候选区域:selective search
抽取图像特征: 利用deep CNN从每个候选区域(region proposal )抽取出一个固定长度(4096-dim)的特征向量(feature vector)
5个卷积层 + 2个全连接层前向传播,删除了源网络最后的1000种分类层(AlexNet)
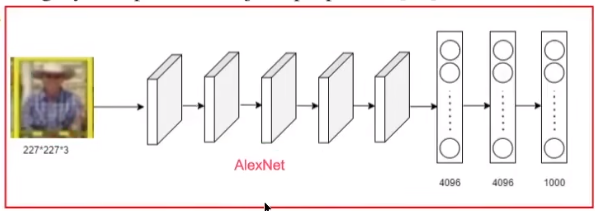
deep CNN要求输入的图片固定大小,因此需要对不同大小的候选区域进行缩放至(227 x 227 RGB)
缩放方法:
- tightest square with context:把整张图片的长边缩放到227,短边按照此比例缩放
- tightest square without context:只把候选区域的长边缩放到227,短边按照此比例缩放
- warp:把候选区域的长短边都直接缩放到227(有形变)(本文√)
用特定类的SVM来对候选区域进行分类:多个二分类构成的SVMs
训练思路
训练特征提取网络
- 有监督预训练:在ImageNet上预训练
- 针对特定领域微调(在VOC数据集上微调出21类的分类模型-softmax层实现分类)
- 网络结构:把ImageNet上训练的CNN(AlexNet)最后一层的1000种分类改成 (N+1) 类的分类层,N为微调的数据集的对象类别数,+1为背景
- 构建数据集:候选区域和ground-truth box的iou > 0.5,为正样本;否则为负样本
- SGD:
- 初始学习率0.001
- 每个iteration,统一采样32个正样本和96个负样本组成128的mini-batch
训练好了分类网络后,就可以在VOC数据集上较好地提取图像特征;在提取特征后,可以训练一个SVM模型,来对候选区域进行分类。
训练SVMs分类器
SVMs是由N个linear SVM构成的,我们需要为每个对象类优化一个linear SVM分类器
- 构建数据集:只把ground truth box作为每个类的正样本;把和ground-truth box的iou < 0.3的候选区域,作为负样本(因为负样本很多,这里采用难负例挖掘策略(hard negative mining method)来进一步挑选)
- 训练分类器:为每个类训练一个linear SVM分类器
测试思路
输入一张图片==》运行selective search产生2000个候选区域(Region proposals)==》缩放成固定大小的proposal==》利用CNN从每个proposal抽取出一个固定长度的feature vector==》用针对特定类的linear SVM分类每一个region proposal==》对每一个类的proposals进行非极大值抑制
可视化
如何可视化高层特征?
在第五个卷积层conv5后跟了一个池化层pool5,经过该于池化层后得到6 x 6 x 256的特征图。提取出一个数据集的所有图像对应的所有候选区域在某一通道某一特定位置的数据进行可视化,实验规律如下:
- 对于高层特征来说,每一个不同的通道,学习到一种高层特征
- 对于同一个通道的不同位置,它表示的特征是相同的,只是边界框的位置有偏移

消融实验
- 在训练CNN的时候,我们使用的是fc7的4096维的输出作为图片的特征,那能不能使用fc6的输出,或pool5的输出作为提取到的特征呢?
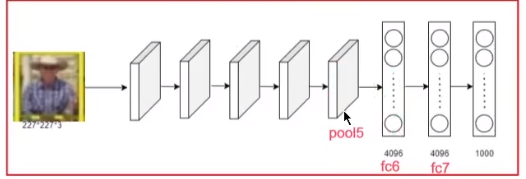
使用微调和不使用微调对最终的精度有没有影响?
在1中选取不同层的输出作为图片的特征的基础上,测试微调后的精度如何改变。实验结果发现:
(1)微调后精度提高,说明微调重要;
(2)在使用全连接层特征、不同层的卷积特征分别进行微调的基础上,发现使用全连接层特征微调后的精度改善更明显,说明微调更多改善的是全连接层的特征提取能力
不同的CNN结构对特征提取效果有什么影响?
对比了AlexNet(本文)、VGG(更复杂)两种CNN结构提取特征的效果,实验结果发现:
VGG更复杂,提取到的特征更好,检测的准确率也更高
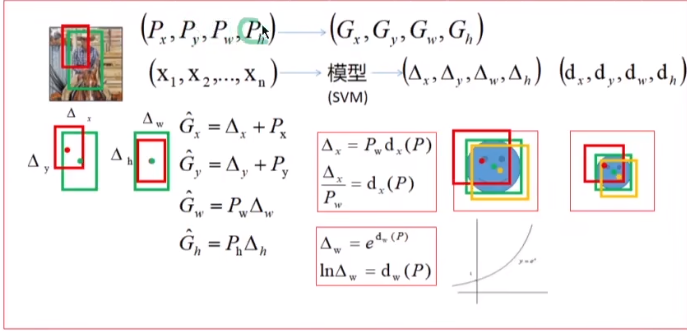
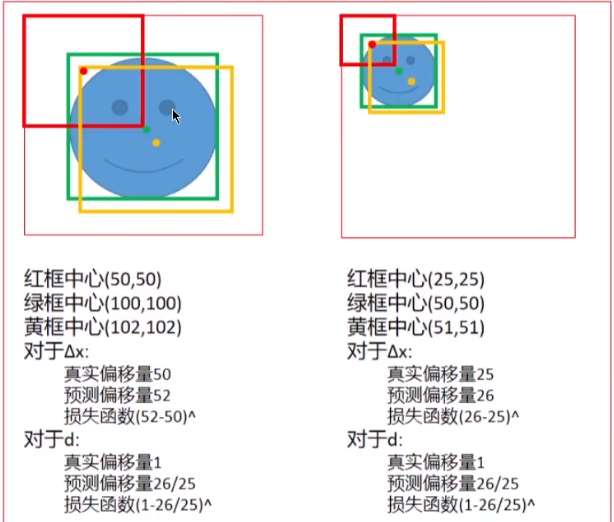
边界框回归
因为我们在进行目标检测,所以不仅要实现分类,还要对目标的边界框进行回归。因此,在提取出CNN特征(这里用的pool5层的特征)后又训练了一个SVM模型,用于回归出目标的边界框,即原始的候选区域到真实框的偏移量。而在实际实验中发现,分类的预测精度较高,但目标的位置预测并不准确。也就是说,我们希望预测框(黄框)尽可能接近真实框(绿框),即损失函数尽可能小
因此要解决的问题变成了:已知一个不准确的位置,要预测出一个准确的位置(从黄框变成绿框)。
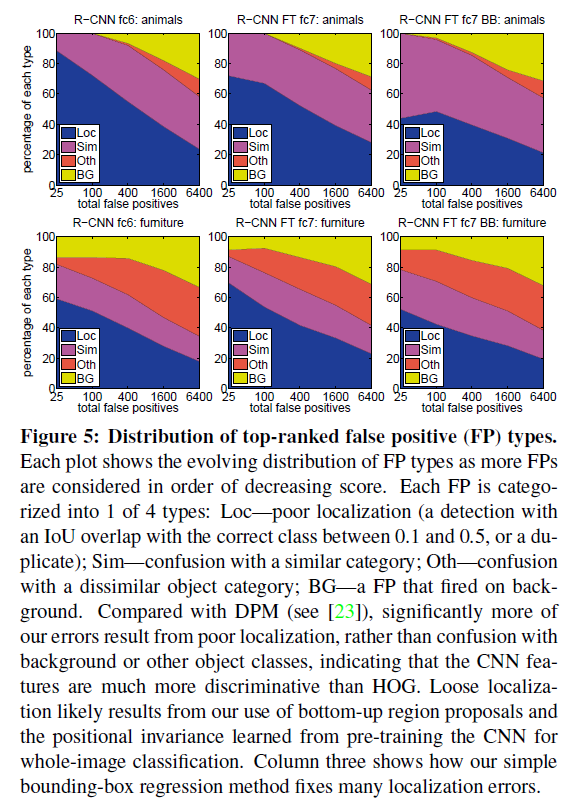
错检情况分析
分析以下四类错误的占比情况
- 类别正确,但位置不准确
- 类别识别为相似类
- 类别识别明显错误
- 目标误识别为类别
检测不同因素对算法的敏感度影响(看不懂)
实验设置的一些问题解释
- 为什么CNN和SVM的正负例定义的方法不同
- 实验观察:通过实验先确定了SVM的划分方法,然后才确定了CNN的正负样本的划分方法
- 理论解释:训练CNN要求的参数很多,需要大量的训练样本。如果也采用训练SVM时采用的正负样本策略,即只把ground truth的标注框作为每个类的正样本,iou < 0.3的候选区域为负样本,这样训练样本就太少了;而采用另外的方法,即iou > 0.5的候选区域为正样本,否则为负样本,能够在标注框附近引入大量的抖动样本,丰富的数据量可以避免CNN过拟合
- 在微调之后明明已经能够对候选区域进行多分类了,后面训练SVMs的部分能不能去掉?
- 实验观察:直接用CNN的softmax层分类会让精度降低
- 解释:
- CNN在训练时使用的正样本(抖动样本)并不是每个目标的精确位置,可能会导致误差 富的数据量可以避免CNN过拟合
- 在微调之后明明已经能够对候选区域进行多分类了,后面训练SVMs的部分能不能去掉?
- 实验观察:直接用CNN的softmax层分类会让精度降低
- 解释:
- CNN在训练时使用的正样本(抖动样本)并不是每个目标的精确位置,可能会导致误差
- 在训练CNN时的负样本是被随机挑选的,而我们可以从CNN分类错误的样本中去挑选那些难负样本,让SVM训练,这样也让增加SVMs分类器后的训练效果更好
参考资料: https://www.bilibili.com/video/BV1CZ4y1a7NP/?spm_id_from=333.1007.top_right_bar_window_history.content.click&vd_source=66a72b15abe9693bd8b4f738f5a67ee7