《动手学深度学习2.0》学习笔记(三)
《动手学深度学习2.0》学习笔记(三)
《动手学深度学习2.0》电子书的链接地址为https://zh.d2l.ai/index.html
本文记录了我在学习本书8-10章节(包括循环神经网络、现代循环神经网络、注意力机制)过程中的理解和收获。
循环神经网络
引言
data:表格数据、图像数据、序列数据。
- 对于表格数据和图像数据,我们默认所有样本都是独立同分布的
- 表格数据:通常利用机器学习、多层感知机处理
- 图像数据:通常利用卷积神经网络(可以有效利用空间信息)
- 序列数据:循环神经网络(recurrent neural network,RNN)
处理序列数据的统计工具
在处理序列数据时,我们面对的问题是——如何有效估计\(P(x_t\mid x_{t-1},\ldots,x_1)\),这需要专门的统计工具,两种较流行的选择是自回归模型和隐变量自回归模型。
自回归模型
自回归模型
第一种策略,假设在现实情况下相当长的序列\(x_{t-1},\ldots,x_1\)可能是不必要的,因此我们只需要满足某个长度为\(\tau\)的时间跨度,即使用观测序列\(x_{t-1},\ldots,x_{t-\tau}\)。当下获得的最直接的好处就是参数的数量总是不变的,至少在\(t>\tau\)时如此,这就使我们能够训练一个上面提及的深度网络。这种模型被称为自回归模型 (autoregressive models) , 因为它们是对自己执行回归。
隐变量自回归模型
第二种策略,如图所示,是保留一些对过去观测的总结\(h_t\), 并且同时更新预测\(\hat{x}_{t}\)和总结\(h_{t}\)。由于\(h_t\)从未被观测到,这类模型也被称为隐变量自回归模型 (latent autoregressive models) 。 \[ \hat{x}_t=P(x_t\mid h_t) \]
\[ h_t=g(h_{t-1},x_{t-1}) \]
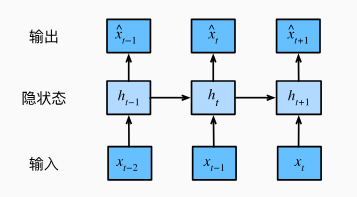
因此,整个序列的估计值都将通过以下的方式获得:
\[ P(x_1,\ldots,x_T)=\prod_{t=1}^TP(x_t\mid x_{t-1},\ldots,x_1). \] 注意,如果我们处理的是离散的对象(如单词), 而不是连续的数字,则上述的考虑仍然有效。唯一的差别是,对于离散的对象,我们需要使用分类器而不是回归模型来估计\(P(x_t\mid x_{t-1},\ldots,x_1)\)。
马尔可夫模型
当序列满足一阶马尔可夫模型(first-order Markov model)时,\(P(x)\)由下式给出: \[ P(x_1,\ldots,x_T)=\prod_{t=1}^TP(x_t\mid x_{t-1}){\text{当}}P(x_1\mid x_0)=P(x_1). \] 当假设\(x_t\)仅是离散值时,可以推导出以下结论: \[ P(x_{t+1}|x_t,x_{t-1})=P(x_{t+1}|x_t) \] 含义是,在满足了前一个状态 \(x_t\) 的条件下,当前状态 \(x_{t+1}\) 的概率分布与更早的历史状态 \(x_{t-1}\) 无关。这个表达式揭示了马尔可夫性质的一种特殊情况,即当前状态的概率分布仅仅依赖于前一个状态。换句话说,给定了前一个状态 \(x_t\) 后,更早的历史状态 \(x_{t-1}\) 对于预测当前状态 \(x_{t+1}\) 的概率分布没有直接的影响。
文本预处理
文本的常见预处理步骤包括:
- 读取数据集:将文本作为字符串加载到内存中。
- 词元化:将字符串拆分为词元(如单词和字符)。
- 语料(corpus):将训练集中的所有文档合并在一起,对它们的唯一词元进行统计, 得到的统计结果称之为语料(corpus)
- 未知词元:“
”,用于映射语料库中不存在或已删除的任何词元 - 其他保留词元:填充词元(“
”); 序列开始词元(“ ”); 序列结束词元(“ ”)
- 建立词表:建立一个词表,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
构建数据集
对于语言建模任务,模型的目标就是预测序列中每一个位置的下一个词元。因此对于每个小批量,我们都需要产生一个源序列(X)以及相应的目标序列(Y),目标序列是源序列向右移动了一个位置的序列。下面描述两种构造数据集的策略,分别是随机采样(random sampling)和 顺序分区(sequential partitioning)
随机采样
- 选择任意偏移量来指示初始位置
- 在迭代过程中,来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
1 | def seq_data_iter_random(corpus, batch_size, num_steps): |
顺序分区
- 选择任意偏移量来指示初始位置
- 在获得第一个子序列后,后面的子序列都按照顺序来获取
这种方法更加能保证上下文的完整性,从而获得更好的训练效果。
1 | def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save |
循环神经网络
引入
- 使用隐变量模型来估计\(P(x_t\mid x_{t-1},\ldots,x_1)\):
\[ P(x_t\mid x_{t-1},\ldots,x_1)\approx P(x_t\mid h_{t-1}), \]
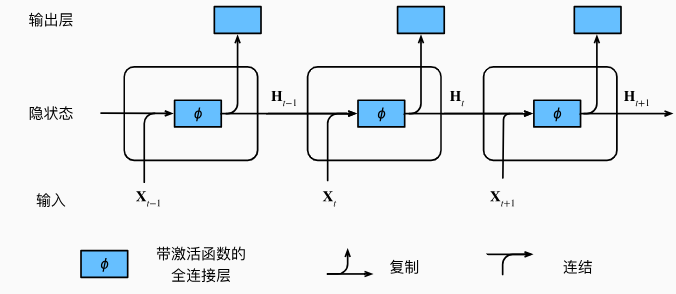
其中\(h_{t-1}\)是隐状态(hidden state), 也称为隐藏变量 (hidden variable), 它存储了到时间步\(t-1\)的序列信息。通常,我们可以基于当前输入\(x_t\)和先前隐状态\(h_{t-1}\) 来计算时间步\(t\)处的任何时间的隐状态: \[ h_t=f(x_t,h_{t-1}). \]
隐藏层和隐状态指的是两个截然不同的概念。隐藏层是在从输入到输出的路径上(以观测角度来理解)的隐藏的层, 而隐状态则是在给定步骤所做的任何事情(以技术角度来定义)的输入, 并且这些状态只能通过先前时间步的数据来计算。
循环神经网络(recurrent neural networks,RNNs) 是具有隐状态的神经网络。
有隐状态的循环神经网络
假设在时间步\(t\)有小批量输入\(\mathbf{X}_t\in\mathbb{R}^{n\times d}\)。换言之,对于\(n\)个序列样本的小批量,\(\mathbf{X}_t\) 的每一行对应于来自该序列的时间步\(t\)处的一个样本。接下来,用\(\mathbf{H}_t\in\mathbb{R}^{n\times h}\) 表示时间步\(t\)的隐藏变量。与多层感知机不同的是,我们在这里保存了前一个时间步的隐藏变量\(\mathbf{H}_{t-1}\),并引入了一个新的权重参数\(\mathbf{W}_{hh}\in\mathbb{R}^{h\times h}\), 来描述如何在当前时间步中使用前一个时间步的隐藏变量。具体地说,当前时间步隐藏变量由当前时间步的输入与前一个时间步的隐藏变量一起计算得出:
\[ \mathbf{H}_t=\phi(\mathbf{X}_t\mathbf{W}_{xh}+\mathbf{H}_{t-1}\mathbf{W}_{hh}+\mathbf{b}_h). \] 相比于多层感知机的计算,上式添加了一项 \(\mathbf{H}_{t-1}\mathbf{W}_{hh}\), 从而实例化了 \(h_t=f(x_t,h_{t-1})\)。从相邻时间步的隐藏变量\(\mathbf{H}_t\)和 \(\mathbf{H}_{t-1}\)之间的关系可知,这些变量捕获并保留了序列直到其当前时间步的历史信息,就如当前时间步下神经网络的状态或记忆,因此这样的隐藏变量被称为隐状态(hidden state)。
基于循环神经网络的字符级语言模型
下图演示了如何通过基于字符级语言建模的循环神经网络,使用当前的和先前的字符预测下一个字符。设小批量大小为1,批量中的文本序列为“machine”。
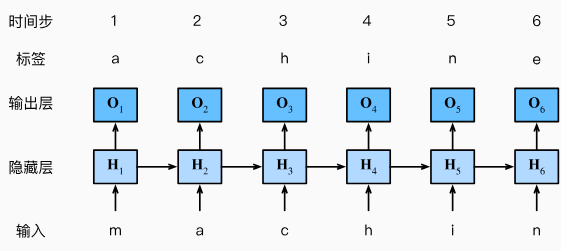
在训练过程中,我们对每个时间步的输出层的输出进行softmax操作,然后利用交叉熵损失计算模型输出和标签之间的误差。由于隐藏层中隐状态的循环计算,上图中的第3个时间步的输出\(\mathbf{O}_{3}\) 由文本序列"m"a"和"c"确定。由于训练数据中这个文本序列的下一个字符是"h", 因此第3个时间步的损失将取决于下一个字符的概率分布,而下一个字符是基于特征序列"n"a"c"和这个时间步的标签"h"生成的。
困惑度(Perplexity)
可以理解为"下一个词元的实际选择数的调和平均数",用于评价语言模型的质量
- 在最好的情况下,模型总是完美地估计标签词元的概率为1。 在这种情况下,模型的困惑度为1。
- 在最坏的情况下,模型总是预测标签词元的概率为0。 在这种情况下,困惑度是正无穷大。
- 在基线上,该模型的预测是词表的所有可用词元上的均匀分布。 在这种情况下,困惑度等于词表中唯一词元的数量。 事实上,如果我们在没有任何压缩的情况下存储序列, 这将是我们能做的最好的编码方式。 因此,这种方式提供了一个重要的上限, 而任何实际模型都必须超越这个上限。
从零实现循环神经网络模型
模型包括3个部分:
输入编码
将每个词元表示为更具表现力的特征向量,最简单的方式为独热编码(one-hot encoding)
循环神经网络模型
实现以下公式: \[ \mathbf{H}_t=\phi(\mathbf{X}_t\mathbf{W}_{xh}+\mathbf{H}_{t-1}\mathbf{W}_{hh}+\mathbf{b}_h). \]
输出生成
训练过程的特点:
- 隐状态初始化:选择随机采样or顺序分区
- 裁剪梯度:在更新模型参数之前需要裁剪梯度。 目的是:即使训练过程中某个点上发生了梯度爆炸,也能保证模型不会发散。
- 模型评估:用困惑度来评价模型,确保了不同长度的序列具有可比性。
通过时间反向传播
- “通过时间反向传播”仅仅适用于反向传播在具有隐状态的序列模型。
- 截断是计算方便性和数值稳定性的需要。截断包括:规则截断和随机截断。
- 矩阵的高次幂可能导致神经网络特征值的发散或消失,将以梯度爆炸或梯度消失的形式表现。
- 为了计算的效率,“通过时间反向传播”在计算期间会缓存中间值。
现代循环神经网络
门控循环单元(GRU)
门控循环单元具有以下两个显著特征:
- 重置门有助于捕获序列中的短期依赖关系;
- 更新门有助于捕获序列中的长期依赖关系。
门控隐状态
门控循环单元与普通的循环神经网络之间的关键区别在于: 前者支持隐状态的门控。 这意味着模型有专门的机制来确定应该何时更新隐状态, 以及应该何时重置隐状态,且这些机制是可学习的。
重置门和更新门
重置门允许我们控制“可能还想记住”的过去状态的数量; 更新门将允许我们控制新状态中有多少个是旧状态的副本。
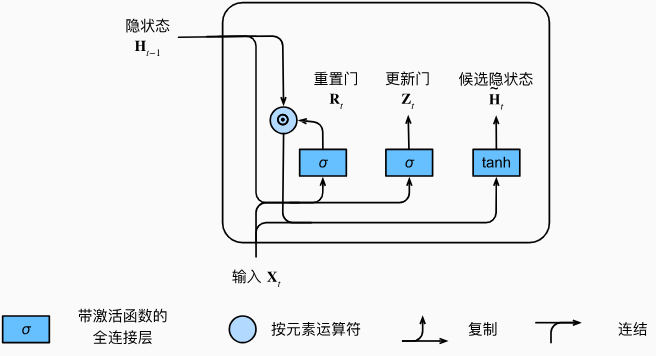
下图描述了门控循环单元中的重置门和更新门的输入, 输入是由当前时间步的输入和前一时间步的隐状态给出。 两个门的输出是由使用sigmoid激活函数的两个全连接层给出。
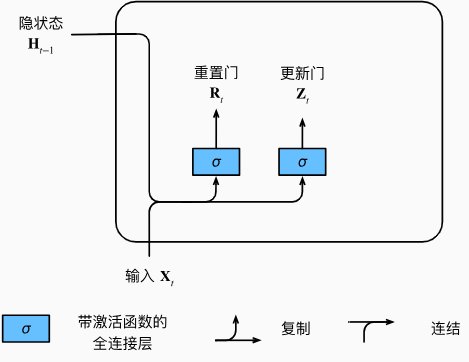
对于给定的时间步\(t\),假设输入是一个小批量 \(\mathbf{X}_t\in\mathbb{R}^{n\times d}\)(样本个数\(n\),输入个数\(d\)),上一个时间步的隐状态是 \(\mathbf{H}_{t-1}\in\mathbb{R}^{n\times h}\quad(\)隐藏单元个数\(h)\) 。那么,重置门\(\mathbf{R}_t\in\mathbb{R}^{n\times h}\)和 更新门\(\mathbf{Z}_t\in\mathbb{R}^{n\times h}\)的计算如下所示:
\[ \begin{gathered} \mathbf{R}_{t} =\sigma(\mathbf{X}_t\mathbf{W}_{xr}+\mathbf{H}_{t-1}\mathbf{W}_{hr}+\mathbf{b}_r), \\ \mathbf{Z}_{t} =\sigma(\mathbf{X}_t\mathbf{W}_{xz}+\mathbf{H}_{t-1}\mathbf{W}_{hz}+\mathbf{b}_z), \end{gathered} \]
其中\(\mathbf{W}_{xr},\mathbf{W}_{xz}\in\mathbb{R}^{d\times h}\)和\(\mathbf{W}_{hr},\mathbf{W}_{hz}\in\mathbb{R}^{h\times h}\)是权重参数,\(\mathbf{b}_r,\mathbf{b}_z\in\mathbb{R}^{1\times h}\)是偏置参数。在求和过程中会触发广播机制;我们使用sigmoid函数将输入值转换到区间(0,1)。
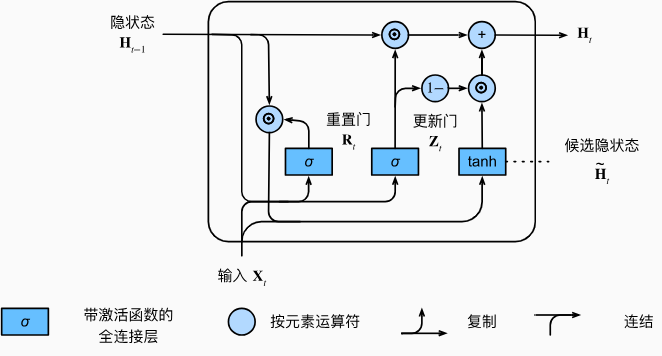
候选隐状态
将重置门\(R_t\)与常规隐状态更新机制\(\mathbf{H}_t=\phi(\mathbf{X}_t\mathbf{W}_{xh}+\mathbf{H}_{t-1}\mathbf{W}_{hh}+\mathbf{b}_h)\)集成,得到在时间步\(t\)的候选隐状态(candidate hidden state)\(\mathbf{\tilde{H}}_t\in\mathbb{R}^{n\times h}\) \[ \tilde{\mathbf{H}}_t=\tanh(\mathbf{X}_t\mathbf{W}_{xh}+(\mathbf{R}_t\odot\mathbf{H}_{t-1})\mathbf{W}_{hh}+\mathbf{b}_h), \] 其中\(\mathbf{W}_{xh}\in\mathbb{R}^{d\times h}\)和\(\mathbf{W}_{hh}\in\mathbb{R}^{h\times h}\)是权重参数,\(\mathbf{b}_h\in\mathbb{R}^{1\times h}\)是偏置项,符号©是Hadamard积 (按元素乘积)运算符。在这里,我们使用tanh非线性激活函数来确保候选隐状态中的值保持在区间(-1,1)中。
- 与常规隐状态更新机制\(\mathbf{H}_t=\phi(\mathbf{X}_t\mathbf{W}_{xh}+\mathbf{H}_{t-1}\mathbf{W}_{hh}+\mathbf{b}_h)\)相比,新的候选隐状态公式中\((\mathbf{R}_t\odot\mathbf{H}_{t-1})\)可以减少以往状态的影响。
- 当重置门\(\mathbf{R}_t\)中接近1时,我们恢复一个如 \(\mathbf{H}_t=\phi(\mathbf{X}_t\mathbf{W}_{xh}+\mathbf{H}_{t-1}\mathbf{W}_{hh}+\mathbf{b}_h)\)的普通的循环神经网络=》重置门打开时,门控循环单元包含基本循环神经网络。
- 对于重置门\(\mathbf{R}_t\)中所有接近0的项,候选隐状态是以\(\mathbf{X}_t\)作为输入的多层感知机的结果。因此,任何预先存在的隐状态都会被重置为默认值。
隐状态
上述的计算结果只是候选隐状态,还需要结合更新门\(\mathbf{Z}_t\),从而确定新的隐状态\(\mathbf{H}_t\in\mathbb{R}^{n\times h}\) 在多大程度上来自旧的状态\(\mathbf{H}_{t-1}\)和 新的候选状态\(\tilde{\mathbf{H}}_{t}\) 。更新门\(\mathbf{Z}_t\)仅需要在 \(\mathbf{H}_{t-1}\)和\(\tilde{\mathbf{H}}_t\) 之间进行按元素的凸组合就可以实现这个目标。这就得出了门控循环单元的最终更新公式:
\[ \mathbf{H}_t=\mathbf{Z}_t\odot\mathbf{H}_{t-1}+(1-\mathbf{Z}_t)\odot\mathbf{\tilde{H}}_t. \]
- 当更新门\({\mathbf{Z}}_t\)接近1时,模型就倾向只保留旧状态。此时,来自\(\mathbf{X}_t\)的信息基本上被忽略,从而有效地跳过了依赖链条中的时间步\(t\)。更新门打开时,门控循环单元可以跳过子序列。
- 相反,当\({\mathbf{Z}}_t\)接近0时,新的隐状态\({\mathbf{H}}_t\)就会接近候选隐状态\(\tilde{\mathbf{H}}_{t}\)。
- 这些设计可以帮助我们处理循环神经网络中的梯度消失问题,并更好地捕获时间步距离很长的序列的依赖关系。例如,如果整个子序列的所有时间步的更新门都接近于1,则无论序列的长度如何,在序列起始时间步的旧隐状态都将很容易保留并传递到序列结束。
长短期记忆网络(LSTM)
长短期记忆网络的隐藏层输出包括“隐状态”和“记忆元”。只有隐状态会传递到输出层,而记忆元完全属于内部信息。
- 记忆元(memory cell ):是LSTM的核心部分,它的主要功能是存储过去的信息。记忆单元内部包含一个称为“细胞状态”的向量,它可以在多个时间步之间保存和传递信息。记忆单元中的sigmoid激活门控单元(例如输入门,遗忘门和输出门)控制信息的存储、读取和遗忘,使得LSTM网络有能力选择性地记住或遗忘历史信息。
- 隐状态:是LSTM的输出部分。在每个时间步,LSTM都会根据当前的输入和过去的隐状态来更新其记忆元,并产生新的隐状态。这个隐状态既反映了当前时间步的输出,也存储了过去的信息,用于产生下一个时间步的输出。
可以理解为:在LSTM模型中,记忆元主要负责存储长期的信息,而隐状态则主要反映短期的动态信息。
- 记忆元中的信息可以经过多个时间步长久地保留,直到模型认为需要忘记这些信息,这就是所谓的“长期记忆”。
- 而隐状态则在每个时间步都会有所更新,既包含了一些过去的信息,又包新的输入信息,这就是所谓的“短期记忆”。只有当这种短期记忆与任务目标密切相关时,它才会被保存到长期记忆中。
门控记忆元
- 记忆元(memory cell 或 cell)是隐状态的一种特殊类型, 它们与隐状态具有相同的形状,其设计目的是用于记录附加的信息。
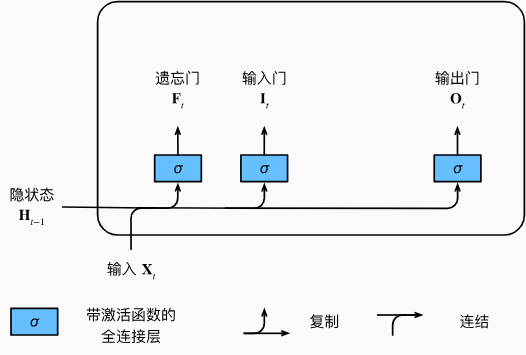
- 为了控制记忆元,我们需要许多门。
- 输出门(output gate):用来从输出门(output gate)中输出条目
- 输入门(input gate):用来决定何时将数据读入记忆元
- 遗忘门(forget gate):用来重置记忆元的内容,决定什么时候记忆或忽略记忆元中的输入
输入门、遗忘门和输出门
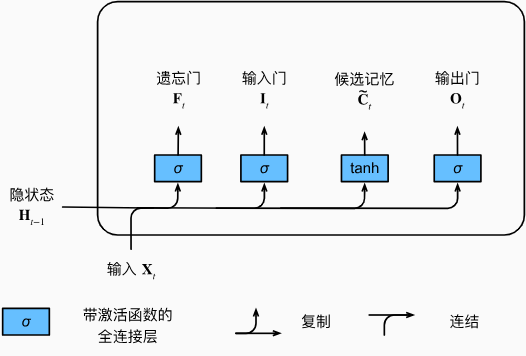
我们来细化一下长短期记忆网络的数学表达。假设有\(h\)个隐藏单元,批量大小为\(n\),输入数为\(d\)。因此,输入为\(\mathbf{X}_t\in\mathbb{R}^{n\times d}\), 前一时间步的隐状态为\(\mathbf{H}_{t-1}\in\mathbb{R}^{n\times h}\)。相应地,时间步\(t\)的门被定义如下:输入门是\(\mathbf{I}_t\in\mathbb{R}^{n\times h}\), 遗忘门是\(\mathbf{F}_t\in\mathbb{R}^{n\times h}\), 输出门是\(\mathbf{O}_t\in\mathbb{R}^{n\times h}\)。它们的计算方法如下: \[ \begin{gathered} I_{t} =\sigma(\mathbf{X}_t\mathbf{W}_{xi}+\mathbf{H}_{t-1}\mathbf{W}_{hi}+\mathbf{b}_i), \\ \mathbf{F}_{t} =\sigma(\mathbf{X}_t\mathbf{W}_{xf}+\mathbf{H}_{t-1}\mathbf{W}_{hf}+\mathbf{b}_f), \\ \mathbf{0}_{t} =\sigma(\mathbf{X}_t\mathbf{W}_{xo}+\mathbf{H}_{t-1}\mathbf{W}_{ho}+\mathbf{b}_o), \end{gathered} \] 其中\(\mathbf{W}_{xi},\mathbf{W}_{xf},\mathbf{W}_{xo}\in\mathbb{R}^{d\times h}\)和\(\mathbf{W}_{hi},\mathbf{W}_{hf},\mathbf{W}_{ho}\in\mathbb{R}^{h\times h}\)是权重参数,\(\mathbf{b}_i,\mathbf{b}_f,\mathbf{b}_o\in\mathbb{R}^{1\times h}\)是偏置参数。
候选记忆元
这里的候选记忆元对应了“短期记忆”的概念。
LSTM模型接收一个新的输入,并结合前一时间步的隐藏状态来更新当前的隐藏状态。这个更新过程就像是对过去信息(即前一时间步的隐藏状态)和新输入信息的一个融合,所以说隐藏状态既包含了一些过去的信息,也包含新的输入信息。这个过程对应了“短期记忆”的概念。
候选记忆元(candidate memory cell) \(\tilde{\mathcal{C}}_t\in\mathbb{R}^{n\times h}\)使用tanh函数作为激活函数,函数的值范围为(-1,1)。下面导出在时间步\(t\)处的方程:
\[ \tilde{\mathbf{C}}_t=\tanh(\mathbf{X}_t\mathbf{W}_{xc}+\mathbf{H}_{t-1}\mathbf{W}_{hc}+\mathbf{b}_c), \]
其中\(\mathbf{W}_{xc}\in\mathbb{R}^{d\times h}\)和\(\mathbf{W}_{hc}\in\mathbb{R}^{h\times h}\)是权重参数,\(\mathbf{b}_c\in\mathbb{R}^{1\times h}\)是偏置参数。
记忆元
- 输入门决定了新的输入信息在多大程度上被写到记忆单元中。如果输入门的值接近1,意味着新的输入信息会被存储到记忆单元里,成为“长期记忆”。
- 遗忘门则对前一时间步的记忆单元进行操作,决定了哪部分历史信息将被遗忘。如果遗忘门的值接近0,那么对应的历史信息就会被遗忘,不再流入下一个时间步的记忆单元。
在长短期记忆网络中,利用输入门和输出门来控制输入和遗忘(或跳过):输入门\(\mathbf{I}_t\)控制采用多少来自\(\tilde{\mathcal{C}}_t\)的新数据,而遗忘门\(\mathbf{F}_t\)控制保留多少过去的记忆元\(\mathbf{C}_{t-1}\in\mathbb{R}^{n\times h}\)的内容。使用按元素乘法,得出:
\[ \mathbf{C}_t=\mathbf{F}_t\odot\mathbf{C}_{t-1}+\mathbf{I}_t\odot\tilde{\mathbf{C}}_t. \] 如果遗忘门\(\mathbf{F}_t\)始终为1且输入门\(\mathbf{I}_t\)始终为0,则过去的记忆元\(\mathcal{C}_{t-1}\)将随时间被保存并传递到当前时间步。引入这种设计是为了缓解梯度消失问题,并更好地捕获序列中的长距离依赖关系。
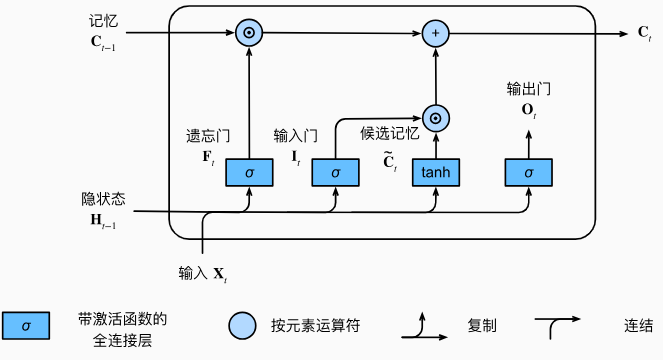
隐状态
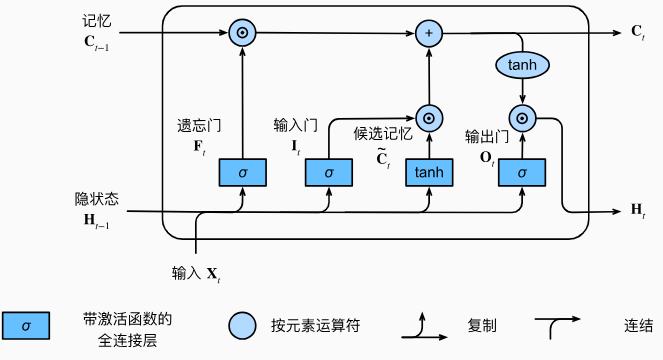
- 输出门决定了多少记忆元的信息会流向隐状态。具体来说,记忆元中的信息首先会与输出门的值(一个在0到1之间的数)相乘,得到的结果就是流向隐藏状态的信息。
- 如果输出门的值接近1,那么记忆元中的信息就几乎完整地流向隐状态;
- 如果输出门的值接近0,那么记忆元中的信息就几乎不会流向隐状态。
这种通过输出门控制信息流向隐状态的机制,使得LSTM模型能够对前面的信息进行选择性的忽略或者强调。例如,在一些情况下,模型可能只需要关注记忆单元中的某一部分信息,那么输出门可以通过关闭(接近0)来阻止其他不相关信息流入隐状态;而在其他情况下,如果记忆单元中的所有信息都对当前任务很重要,那么输出门可以被打开(接近1),这样所有的信息都会流向隐状态。在处理自然语言的任务(如机器翻译、文本生成等)时,通过合理调整输出门的值,可以更好地控制长短语义的流动,从而捕捉到句子中更复杂、更深层次的语义关系。
因此,隐状态\(\mathbf{H}_t\in\mathbb{R}^{n\times h}\)计算公式为:
\[ \mathbf{H}_t=\mathbf{O}_t\odot\tanh(\mathbf{C}_t). \]
只要输出门接近1,我们就能够有效地将所有记忆信息传递给预测部分,而对于输出门接近0,我们只保留记忆元内的所有信息, 而不需要更新隐状态。
深度循环神经网络
(后续需要使用再学习)
双向循环神经网络
(后续需要使用再学习)
编码器-解码器架构
为了处理长度可变的输入和输出序列(如机器翻译),设计了编码器-解码器(encoder-decoder)架构,包含两个主要组件:
(1)编码器(encoder): 接受一个长度可变的序列作为输入, 并将其转换为具有固定形状的编码状态。
(2)解码器(decoder): 将固定形状的编码状态映射到长度可变的序列。
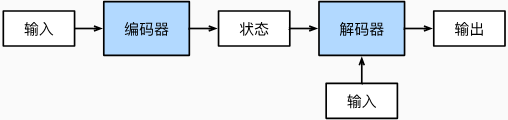
序列到序列学习(seq2seg)
(后续需要使用再学习)
注意力机制
注意力框架=》注意力函数=》仅仅基于注意力机制的Transformer架构
注意力提示
双组件(two-component)框架
受试者基于非自主性提示和自主性提示 有选择地引导注意力的焦点。(心理学)
- 非自主性提示:基于环境中物体的突出性和易见性
- 自主性提示:依赖于认知和意识的控制
查询、键和值
- 在注意力机制的背景下,自主性提示被称为查询(query)
- 感官输入被称为值(value)
- 每个值都与一个键(key)配对, 这可以想象为感官输入的非自主提示。
给定任何查询,注意力机制通过注意力汇聚(attention pooling) 将选择引导至感官输入(sensory inputs,例如中间特征表示)。
如下图所示,可以通过设计注意力汇聚的方式, 便于给定的查询(自主性提示)与键(非自主性提示)进行匹配, 这将引导得出最匹配的值(感官输入)。
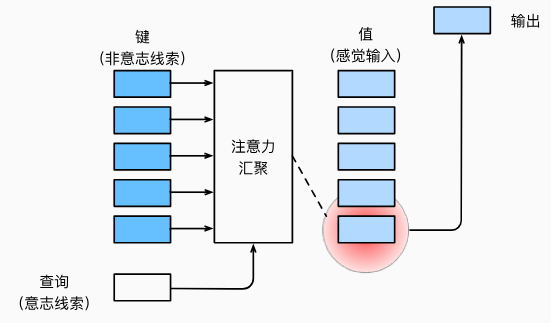
查询(自主提示)和键(非自主提示)之间的交互形成了注意力汇聚; 注意力汇聚有选择地聚合了值(感官输入)以生成最终的输出
可视化注意力
注意力机制的可视化一般是通过在源序列和目标序列之间展示一个热图,该热图的每个单元格[i][j]对应源序列中的第i个元素和目标序列中的第j个词的注意力分数。这个分数表明在生成目标序列的第j个词时模型对源序列中第i个词的关注程度。我们根据注意力分数,画出对应的颜色,数值越高,对应的颜色越明显(或者说越热)。
注意力汇聚
非参数注意力汇聚
Nadaraya-Watson核回归
Nadaraya和 Watson提出根据输入的位置对输出\(y_i\)进行加权,来实现注意力汇聚。其中,K是核(kernel)。 \[ f(x)=\sum_{i=1}^n\frac{K(x-x_i)}{\sum_{j=1}^nK(x-x_j)}y_i, \]
通用的注意力汇聚(attention pooling)公式
由上述公式启发,写出更加通用的注意力汇聚(attention pooling)公式: \[ f(x)=\sum_{i=1}^n\alpha(x,x_i)y_i \] 其中,\(x\)是查询,\((x_i,y_i)\)是键值对,将查询\(x\)和键\(x_i\)之间的关系建模为 注意力权重 (attention weight) \(\alpha(x,x_i)\),这个权重将被分配给每一个对应值\(y_{i}\),因此注意力汇聚\(f(x)\)是\(y_i\)的加权平均。对于任何查询,模型在所有键值的注意力权重都是一个有效的概率分布:它们是非负的,并且总和为1。
Nadaraya-Watson高斯核回归
为了更好地理解注意力汇聚,考虑一个高斯核(Gaussian kernel),其定义为: \[ K(u)=\frac1{\sqrt{2\pi}}\exp(-\frac{u^2}2). \] 将高斯核代上述"Nadaraya-Watson核回归公式"可以得到: \[ \begin{aligned} f(x)& =\sum_{i=1}^n\alpha(x,x_i)y_i \\ &=\sum_{i=1}^n\frac{\exp\left(-\frac12(x-x_i)^2\right)}{\sum_{j=1}^n\exp\left(-\frac12(x-x_j)^2\right)}y_i \\ &=\sum_{i=1}^n\text{softmax}\left(-\frac12(x-x_i)^2\right)y_i. \end{aligned} \] 分析上式,可以得出:如果一个键\(x_i\)越是接近给定的查询\(x\), 那么分配给这个键对应值\(y_i\)的注意力权重就会越大,也就“获得了更多的注意力”。
原因是:如果键\(x_i\)与查询x越接近,\((x - x_i)^2\)就越小,那么分子\(\exp\left(-\frac12(x-x_i)^2\right)\)的值就越大。虽然分母\(\sum_{i=1}^n\exp\left(-\frac12(x-x_j)^2\right)\)的值也会随着分子的变大而变大。然而,那么这个根据糖水不等式可知,最终该项的分数整体会更大,也就是分配给这个键对应值\(y_i\)的注意力权重就会越大,也就“获得了更多的注意力”。
带参数的注意力汇聚
在下面的查询\(x\)和键\(x_i\)之间的距离乘以可学习参数\(w\): \[ \begin{aligned} f(x)& =\sum_{i=1}^n\alpha(x,x_i)y_i \\ &=\sum_{i=1}^n\frac{\exp\left(-\frac12((x-x_i)w)^2\right)}{\sum_{j=1}^n\exp\left(-\frac12((x-x_j)w)^2\right)}y_i \\ &=\sum_{i=1}^n\text{softmax}\left(-\frac12((x-x_i)w)^2\right)y_i. \end{aligned} \]
定义模型
1 | # 导入需要的模块 |
对比非参数和带参数的注意力汇聚
非参数的注意力汇聚 如果有足够的数据,模型会收敛到最优结果。
带参数的注意力汇聚在尝试拟合带噪声的训练数据时, 预测结果不如之前非参数模型的平滑。
注意力评分函数
引入
【注意力汇聚】小节使用了高斯核来对查询和键之间的关系建模。 \[ \begin{aligned} f(x) &=\sum_{i=1}^n\frac{\exp\left(-\frac12((x-x_i)w)^2\right)}{\sum_{j=1}^n\exp\left(-\frac12((x-x_j)w)^2\right)}y_i \\ &=\sum_{i=1}^n\text{softmax}\left(-\frac12((x-x_i)w)^2\right)y_i. \end{aligned} \]
- 其中的高斯核指数部分\(-\frac12((x-x_i)w)^2\)可以视为注意力评分函数(attention scoring function),简称评分函数(scoring function)
- 然后,把这个函数的输出结果输入到softmax函数中进行运算,将得到与键对应的值的概率分布(即注意力权重)
- 最后,注意力汇聚的输出就是基于这些注意力权重的值的加权和
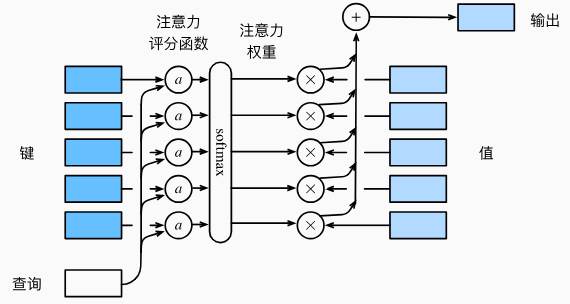
数学描述
用数学语言描述,假设有一个查询\(\mathbf{q}\in\mathbb{R}^q\)和 \(m\)个“键-值"对 \((\mathbf{k}_1,\mathbf{v}_1),\ldots,(\mathbf{k}_m,\mathbf{v}_m)\), 其中\(\mathbf{k}_i\in\mathbb{R}^k\), \(\mathbf{v}_i\in\mathbb{R}^v\)。注意力汇聚函数\(f\)就被表示成值的加权和:
\[ f(\mathbf{q},(\mathbf{k}_1,\mathbf{v}_1),\ldots,(\mathbf{k}_m,\mathbf{v}_m))=\sum_{i=1}^m\alpha(\mathbf{q},\mathbf{k}_i)\mathbf{v}_i\in\mathbb{R}^v, \]
- 观察公式,理解为:通过查询\(q\)和键\(k_i\)的匹配度,得出不同的注意力权重\(\alpha\),从而对与键\(k_i\)对应的值\(v_i\)产生不同的注意力
其中查询\(\mathbf{q}\)和键\(\mathbf{k}_i\)的注意力权重(标量) 是通过注意力评分函数\(a\)将两个向量映射成标量,再经过softmax运算得到的:
\[ \alpha(\mathbf{q},\mathbf{k}_i)=\mathrm{softmax}(a(\mathbf{q},\mathbf{k}_i))=\frac{\exp(a(\mathbf{q},\mathbf{k}_i))}{\sum_{j=1}^m\exp(a(\mathbf{q},\mathbf{k}_j))}\in\mathbb{R}. \]
因此,选择不同的注意力评分函数\(a\)会导致不同的注意力汇聚操作。下面将介绍两个流行的评分函数, 稍后将用他们来实现更复杂的注意力机制。
常用评分函数
加性注意力
一般来说,当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。给定查询\(\mathbf{q}\in\mathbb{R}^q\)和 键\(\mathbf{k}\in\mathbb{R}^k\), 加性注意力 (additive attention) 的评分函数为
\[ a(\mathbf{q},\mathbf{k})=\mathbf{w}_v^\top\mathrm{tanh}(\mathbf{W}_q\mathbf{q}+\mathbf{W}_k\mathbf{k})\in\mathbb{R}, \]
- 其中可学习的参数是\(\mathbf{W}_q\in\mathbb{R}^{h\times q}\)、\(\mathbf{W}_k\in\mathbb{R}^{h\times k}\)和\(\mathbf{w}_v\in\mathbb{R}^h\)。
- 公式解释:将查询和键连结起来后输入到一个多层感知机(MLP) 中,感知机包含一个隐藏层,其隐藏单元数是一个超参数\(h\),使用tanh作为激活函数,并且禁用偏置项。
缩放点积注意力
查询和键具有相同的长度\(d\)(前提条件),可以使用点积这一计算效率更高的评分函数。
假设查询和键的所有元素都是独立的随机变量,并且都满足零均值和单位方差,那么两个向量的点积的均值为0,方差为\(d\) 。为确保无论向量长度如何,点积的方差在不考虑向量长度的情况下仍然是1,我们再将点积除以\(\sqrt d\),则缩放点积注意力 (scaled dot-product attention) 评分函数为:
\[ a(\mathbf{q},\mathbf{k})=\mathbf{q}^\top\mathbf{k}/\sqrt d. \]
在实践中,我们通常从小批量的角度来考虑提高效率,例如基于\(n\)个查询和\(m\)个键一值对计算注意力,其中查询和键的长度为\(d\),值的长度为\(v\)。查询\(\mathbf{Q}\in\mathbb{R}^{n\times d}\)、键\(\mathbf{K}\in\mathbb{R}^{m\times d}\)和 值\(\mathbf{V}\in\mathbb{R}^{m\times v}\)的缩放点积注意力是:
\[ \operatorname{softmax}\left(\frac{\mathbf{QK}^\top}{\sqrt{d}}\right)\mathbf{V}\in\mathbb{R}^{n\times v}. \]
Bahdanau 注意力
引入
在机器翻译问题中:通过设计一个基于两个循环神经网络的编码器-解码器架构, 用于序列到序列学习。
具体来说,循环神经网络编码器将长度可变的序列转换为固定形状的上下文变量, 然后循环神经网络解码器根据生成的词元和上下文变量 按词元生成输出(目标)序列词元。然而,并非所有输入(源)词元都对解码某个词元有用, 那么在每个解码步骤中使用编码不同的上下文变量是否会更合理呢?
在这里,我们可以将上下文变量视为注意力集中的输出。 在预测词元时,如果不是所有输入词元都相关,模型将仅对齐输入序列中与当前预测相关的部分。
Bahdanau 注意力模型
原来的机器翻译问题中,解码器的隐藏层的变换为: \[ \mathbf{s}_{t^{\prime}}=g(y_{t^{\prime}-1},\mathbf{c},\mathbf{s}_{t^{\prime}-1}). \] 在输出序列上的任意时间步\(t^{\prime}\), 循环神经网络将来自上一时间步的输出\(y_{t^{\prime}-1}\) 和上下文变量\(c\)作为其输入,然后在当前时间步将它们和上一隐状态 \(\mathfrak{s}_{t^{\prime}-1}\)转换为 隐状态\(s_{t^{\prime}}\)。
在理解上述【引入】部分的思路后,假设输入序列中有\(T\)个词元,解码时间步\(t^{\prime}\)的上下文变量是注意力集中的输出: \[ \mathbf{c}_{t^{\prime}}=\sum_{t=1}^T\alpha(\mathbf{s}_{t^{\prime}-1},\mathbf{h}_t)\mathbf{h}_t, \] 其中,时间步\(t^{\prime}-1\)时的解码器隐状态\(\mathfrak{s}_{t^{\prime}-1}\)是查询,编码器隐状态\(\mathfrak{h}_t\)既是键,也是值,注意力权重\(\alpha\)是使用加性注意力打分函数计算的。
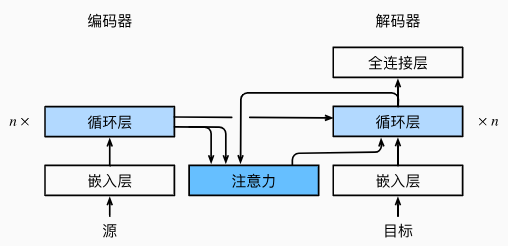
定义注意力解码器
定义Bahdanau注意力,实现循环神经网络编码器-解码器。
- 首先,初始化解码器的状态,需要下面的输入:
- 用编码器在所有时间步的最终层隐状态作为注意力的键和值
- 用上一时间步的编码器全层隐状态作为初始化解码器的隐状态
- 编码器有效长度(排除在注意力池中填充词元)
- 其次,进行查询
- 在每个解码时间步骤中,解码器上一个时间步的最终层隐状态将用作查询。
多头注意力
引入
在实践中,当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。因此,允许注意力机制组合使用查询、键和值的不同 子空间表示 (representation subspaces) 可能是有益的。
为此,与其只使用单独一个注意力汇聚,我们可以用独立学习得到的\(h\)组不同的 线性投影 (linear projections) 来变换查询、键和值。然后,这\(h\)组变换后的查询、键和值将并行地送到注意力汇聚中。最后,将这\(h\)个注意力汇聚的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换,以产生最终输出。
这种设计被称为多头注意力 (multihead attention) 。对于\(h\)个注意力汇聚输出, 每一个注意力汇聚都被称作一个头(head)。多头注意力融合了来自于多个注意力汇聚的不同知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。
下图展示了使用全连接层来实现可学习的线性变换的多头注意力。
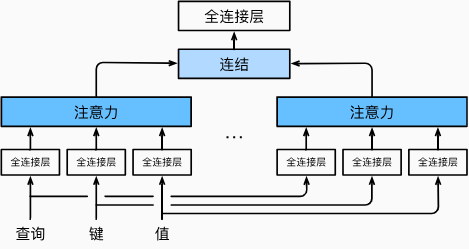
数学描述
用数学语言描述上述多头注意力模型:
给定查询\(\mathbf{q}\in\mathbb{R}^{d_q}\)、键\(\mathbf{k}\in\mathbb{R}^{d_k}\)和 值\(\mathbf{v}\in\mathbb{R}^{d_v}\), 每个注意力头\(\mathbf{h}_i\quad(i=1,\ldots,h)\) 的计算方法为:
\[ \mathbf{h}_i=f(\mathbf{W}_i^{(q)}\mathbf{q},\mathbf{W}_i^{(k)}\mathbf{k},\mathbf{W}_i^{(v)}\mathbf{v})\in\mathbb{R}^{p_v}, \]
其中,可学习的参数包括\(\mathbf{W}_i^{(q)}\in\mathbb{R}^{p_q\times d_q}\text{、}\mathbf{W}_i^{(k)}\in\mathbb{R}^{p_k\times d_k}\text{和 }\mathbf{W}_i^{(v)}\in\mathbb{R}^{p_v\times d_v}\),以及代表注意力汇聚的函数\(f\)。\(f\)可以是加性注意力和缩放点积注意力。
多头注意力的输出需要经过另一个线性转换,它对应着\(h\)个头连结后的结果,因此其可学习参数是 \(\mathbf{W}_o\in\mathbb{R}^{p_o\times hp_v}:\)
\[ \mathbf{W}_o\begin{bmatrix}\mathbf{h}_1\\\vdots\\\mathbf{h}_h\end{bmatrix}\in\mathbb{R}^{p_o}. \] 基于这种设计,每个头都可能会关注输入的不同部分,从而可以表示比简单加权平均值更复杂的函数。
自注意力和位置编码
引入
在深度学习中,经常使用卷积神经网络(CNN)或循环神经网络(RNN)对序列进行编码。有了注意力机制之后,我们将词元序列输入注意力池化中,以便同一组词元同时充当查询、键和值。具体来说,每个查询都会关注所有的键一值对并生成一个注意力输出。由于查询、键和值来自同一组输入,因此被称为 自注意力 (self-attention) ,也被称为内部注意力 (intra-attention)。
自注意力
给定一个由词元组成的输入序列\(\mathbf{x}_1,\ldots,\mathbf{x}_n\), 其中任意\(\mathbf{x}_i\in\mathbb{R}^d\quad(1\leq i\leq n)\) 。该序列的自注意力输出为一个长度相同的序列 \(\mathbf{y}_1,\ldots,\mathbf{y}_n\),其中:
\[ \mathbf{y}_i=f(\mathbf{x}_i,(\mathbf{x}_1,\mathbf{x}_1),\ldots,(\mathbf{x}_n,\mathbf{x}_n))\in\mathbb{R}^d \]
1 | attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens, |
MultiHeadAttention模型在接收输入时,传入的查询(query)、键(key)和值(value)都是相同的张量X。这意味着模型在计算注意力分数时,输入序列的各个元素同时扮演了查询、键和值的角色,也就是自己对自己进行注意力计算,因此被称为"自注意力"。
比较卷积神经网络、循环神经网络和自注意力
比较卷积神经网络、循环神经网络和自注意力这3种架构的计算复杂性、顺序操作和最大路径长度。
- 计算复杂性:
指进行运算所需要的计算量。我们通常希望计算复杂性越低越好,因为这意味着需要的计算资源更少,训练和预测的速度也更快。
- 卷积神经网络:计算复杂性为\(O(knd^2)\),其中k是卷积核的大小,n是序列长度,d是输入和输出的通道数。换言之,卷积神经网络所需要的计算量与卷积核的大小、序列长度以及输入和输出的通道数有关。
- 循环神经网络:计算复杂性为\(O(nd^2)\),其中n是序列长度,d是隐藏状态的维度。因此,循环神经网络所需要的计算量与序列长度和隐藏状态的维度有关。
- 自注意力机制:计算复杂性为\(O(n^2d)\),其中n是序列长度,d是输入输出的维度。对于自注意力机制,计算量与序列长度的平方和输入输出的维度有关。
- 顺序操作:
顺序操作是指必须按照特定顺序进行的操作。顺序操作的数量越多,越难以进行并行计算,因此我们通常希望顺序操作越少越好。
- 卷积神经网络和自注意力机制的顺序操作数量都为$ O (1)$,也就是说,几乎不存在顺序操作,计算可以高度并行化。
- 循环神经网络的顺序操作数量为\(O (n)\),也就是说,它需要按照序列数据(长度为n)的顺序,一个接一个地处理每个元素——先处理第一个元素,然后处理第二个元素,然后处理第三个元素,依此类推。也就是说,无法同时处理所有的序列元素,因为每个步骤都依赖于前一个步骤的输出,因此无法进行完全的并行计算。这就导致了RNN的主要缺点——在处理长序列时可能会很慢,因为必须等待所有的顺序操作都完成才能得到最终的输出。
- 最大路径长度:
最大路径长度是指在网络中,从一个节点到另一个节点经过的最大路径长度。路径越短,网络学习序列中远距离依赖关系的能力越好。
- 卷积神经网络的最大路径长度为 \(O (n/k)\),n是序列长度,k是卷积核的大小。
- 循环神经网络的最大路径长度为 \(O (n)\),n是序列长度。
- 自注意力机制的最大路径长度为 \(O (1)\),也就是说,任何两个节点之间的距离都为 1。
总结一下,卷积神经网络和自注意力机制可以进行高度的并行计算,而自注意力机制的最大路径长度最短。然而,自注意力机制的计算复杂性与序列长度的平方成正比,因此在处理长序列时可能会很慢。
位置编码
引入
在处理词元序列时,循环神经网络是逐个的重复地处理词元的,而自注意力则因为并行计算而放弃了顺序操作。为了使用序列的顺序信息,通过在输入表示中添加 位置编码 (positional encoding) 来注入绝对的或相对的位置信息。位置编码可以通过学习得到也可以直接固定得到。接下来介绍基于正弦函数和余弦函数的固定位置编码
基于正弦函数和余弦函数的固定位置编码
假设输入表示\(\mathbf{X}\in\mathbb{R}^{n\times d}\)包含一个序列中\(n\)个词元的\(d\)维嵌入表示。位置编码使用相同形状的位置嵌入矩阵 \(\mathbf{P}\in\mathbb{R}^{n\times d}\)输出\(\mathbf{X}+\mathbf{P}\), 矩阵第\(i\)行、第\(2j\)列和\(2j+1\)列上的元素为:
\[ \begin{gathered} p_{i,2j} =\sin\left(\frac i{10000^{2j/d}}\right), \\ p_{i,2j+1} =\cos\left(\frac i{10000^{2j/d}}\right). \end{gathered} \] 这里利用了正弦函数和余弦函数的连续性和周期性,来为每个位置生成一个固定的编码。具体来说,对于每一个位置i(也就是序列中的第i个词元):
- 我们为它的每一个维度(指该词元对应的词嵌入向量的每一个元素)生成一个位置编码。
- 如果这个维度是偶数(\(2j\)),那么使用正弦函数生成位置编码
- 如果这个维度是奇数(\(2j+1\)),那么使用余弦函数生成位置编码。
- 函数的输入是位置i和维度j,通过这种方法可以为每个位置生成一个唯一的编码。
之所以使用正弦函数和余弦函数主要归功于它们的周期性和连续性。周期性是指函数的值会在每个完整的周期内重复。连续性是指在实数范围内,函数的图像是无间断的。
当用于位置编码时,正弦和余弦函数可以非常好地表达出序列中单词的相对位置关系。
- 相邻的单词位置的差距较小,对应的正弦或余弦值的变化也相近(连续性)
- 相反,序列中距离较远的单词对应的输入数值差距较大,他们的正弦和余弦值的变化也会相对较大(实际中并不直接使用单一的正弦或余弦函数来表达位置信息,而是使用了一系列不同波长的正弦和余弦函数,使得任意两个位置的编码都是唯一的,即使是在很远的序列位置,也能得到有区别性的编码。)
正弦和余弦函数的这些特性让编码的变化能够反映出单词在序列中位置的改变,这种改变可能是相邻位置的微小变动,也可能是较长距离的较大变动。这就使得模型可以捕捉到语言序列中单词之间的相对位置关系,这对于理解和生成语言非常重要。
Transformer
自注意力同时具有并行计算和最短的最大路径长度这两个优势,因此,使用自注意力来设计深度架构很有吸引力。对比之前仍然依赖循环神经网络实现输入表示的自注意力模型,Transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络层。
模型
Transformer作为编码器一解码器架构的一个实例,其整体架构图如下图所示。与基于Bahdanau注意力实现的序列到序列的学习相比,Transformer的编码器和解码器是基于自注意力的模块叠加而成的,源(输入) 序列和目标(输出)序列的嵌入(embedding) 表示将加上位置编码 (positional encoding),再分别输入到编码器和解码器中。
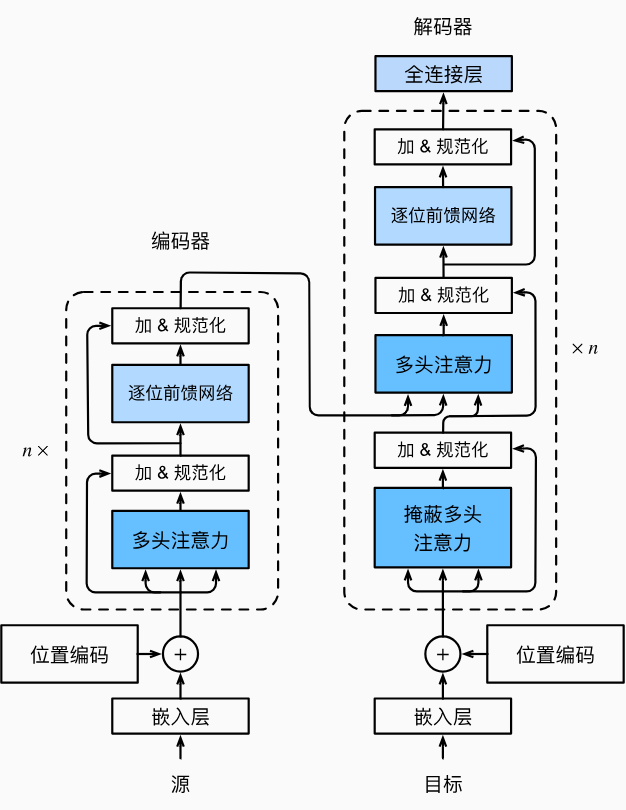
Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层 (子层表示为sublayer)。
子层一:多头自注意力 (multi-head self-attention) 汇聚层。
该层将输入进行了分组处理,每一组分别通过自注意力机制处理后,多个结果又会合并为一组新的编码输出。这个子层主要负责提取输入中的全局依赖关系。
子层二:位置前馈网络 (positionwise feed-forward network)层。
该层会对每个输入位置对应的编码进行独立的处理,频繁地学习到输入的非线性表示。
残差连接 (residual connection):这种机制引入了“短路”机制,使得神经网络的每层的输入都能直接影响每层的输出,并传播到更深的层次。这种机制有效地缓解了梯度消失/梯度爆炸问题。
层规范化 (layer normalization): 这个操作将得到的残差结果进行了规范化处理,以调整它们的值范围,从而提升模型训练的稳定性。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。
- 除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层(通常被隐式地包含在解码器中的“自注意力(Self-Attention)”),称为 编码器一解码器注意力 (encoder-decoder attention) 层。在编码器—解码器注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。
- 解码器的自注意力层使用了一个掩蔽机制,以防止预测位置看到后面的位置,这就保证了解码的自回归性质,使得当前输出仅依赖于产生的前面的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。
位置前馈网络
这里的"前馈网络"其实只是一个特别普通的多层感知机,而"位置前馈网络"特殊就特殊在这个"位置",这个"位置"是指这个"前馈网络"会被独立地应用于输入序列的每一个元素。也就是说,对于输入序列中的每一个位置,我们都会独立地应用同一个前馈网络。从而实现——将元素对应的原有的词向量变换为多层感知机(MLP)处理后的新的词向量。
这一变换的意义是:
- 首先,原有的词向量通常是词的静态表示,在特定上下文中,一个词的含义可能会有所变化。通过这种变换,我们可以得到词在特定上下文中的动态表示,这对于理解和生成上下文相关的句子非常有帮助。
- 另外,这种变换也是增加模型复杂性的一种方式,可以使模型具有更强的表达能力。多层感知机(MLP)可以理解为对输入数据的一种非线性变换,通过多个这样的非线性变换,我们可以得到输入数据的一个更抽象、更复杂的表示。就好像我们看一个物体,可以从不同的角度(即语境)获得关于这个物体的不同信息,这种变化使我们对物体的理解更深入、更全面。
- 这是一种一对一的映射关系,为每个位置提供了一个密集的变换。在这一点上,它类似于卷积层,因为卷积层也会对输入数据的每一个位置分别进行映射,不过它的映射函数是依赖于邻域的,而前馈网络则更加简单,它的映射函数仅依赖于那一个位置的数据。
残差连接和层规范化
残差连接
残差连接(Residual Connection)也被称为跳过连接,是一种让前面层的信息能够直接流向后面层的方法。在Transformer中,每一层的输入都会与该层的输出进行元素级别的相加操作,这种操作就构成了一种残差连接。残差连接的主要作用是缓解梯度消失问题,使得深层网络的训练变得更加稳定。当网络深度较大时,前向传播和反向传播都可能会遇到数值不稳定性问题,残差连接可以允许梯度直接反向传播到任何一层。
层规范化
层规范化(Layer Normalization)是一种对神经网络中的隐藏层进行规范化的方法,并且层规范在一个样本内部进行,这意味着对于同一层的每个神经元来说,其规范化的统计量(均值、方差)是相同的。主要有两个作用:一是加速模型收敛速度,稳定模型训练;二是具有一定的正则化效果,避免模型过拟合。在Transformer中,将层规范化应用于残差连接后的结果,有助于网络更好地学习和适应数据集的特性。
编码器
编码器EncoderBlock类包含两个子层:多头自注意力和基于位置的前馈网络,这两个子层都使用了残差连接和紧随的层规范化。
1 | class EncoderBlock(nn.Module): |
1 | class AddNorm(nn.Module): |
解码器
在解码器DecoderBlock类中实现的每个层包含了三个子层:解码器自注意力、“编码器-解码器”注意力和基于位置的前馈网络。这些子层也都被残差连接和紧随的层规范化围绕。
1 | class DecoderBlock(nn.Module): |
小结
- Transformer是编码器-解码器架构的一个实践,尽管在实际情况中编码器或解码器可以单独使用。
- 在Transformer中,多头自注意力用于表示输入序列和输出序列,不过解码器必须通过掩蔽机制来保留自回归属性。
- Transformer中的残差连接和层规范化是训练非常深度模型的重要工具。
- Transformer模型中基于位置的前馈网络使用同一个多层感知机,作用是对所有序列位置的表示进行转换。