《动手学深度学习2.0》学习笔记(五)
《动手学深度学习2.0》学习笔记(五)
《动手学深度学习2.0》电子书的链接地址为https://zh.d2l.ai/index.html
本文记录了我在学习本书第11章节(优化算法)过程中的理解和收获。
优化算法
深度学习中出现的几乎所有优化问题都是非凸的,但是如果算法在凸性条件设定下的效果很差, 那通常我们很难在其他条件下看到好的结果。所以,在凸问题背景下设计和分析算法是非常有启发性的。
优化和深度学习
优化目标
对于深度学习问题,我们首先定义损失函数。有了损失函数,我们就可以使用优化算法来尝试最小化损失。在优化中,损失函数通常被称为优化问题的目标函数。
尽管优化提供了一种最大限度地减少深度学习损失函数的方法,但本质上,优化和深度学习的目标是根本不同的。前者主要关注的是最小化目标,后者则关注在给定有限数据量的情况下寻找合适的模型。
具体来说
- 由于优化算法的目标函数是基于训练集的损失函数,因此优化的目标是减少训练误差。
- 然而,深度学习(或更广义地说,统计推断)的目标是减少泛化误差。
为了减少泛化误差,除了使用优化算法来减少训练误差之外,还需要注意过拟合。
优化挑战
局部最小值
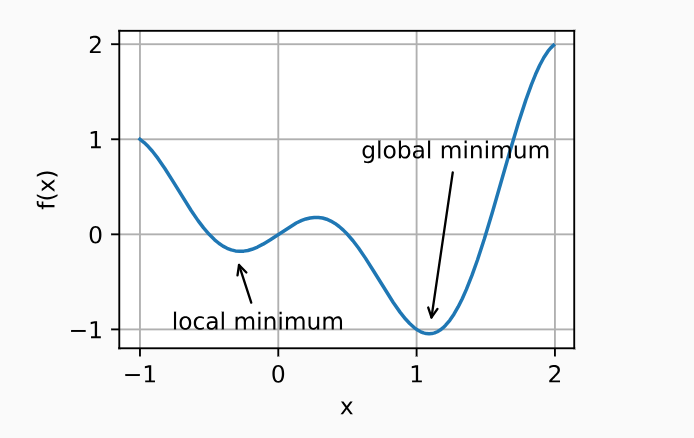
解决:小批量随机梯度下降,小批量上梯度的自然变化能够将参数从局部极小值中跳出。
鞍点
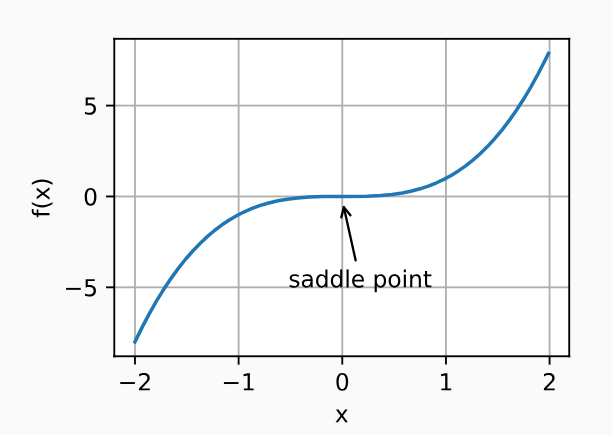
现象:鞍点(saddle point)是指函数的所有梯度都消失但既不是全局最小值也不是局部最小值的任何位置。
梯度消失
用sigmoid激活函数经常会因为梯度消失导致优化停滞,引入ReLU激活函数后有了极大改善。
凸性
虽然深度学习中的优化问题通常是非凸的, 它们也经常在局部极小值附近表现出一些凸性。
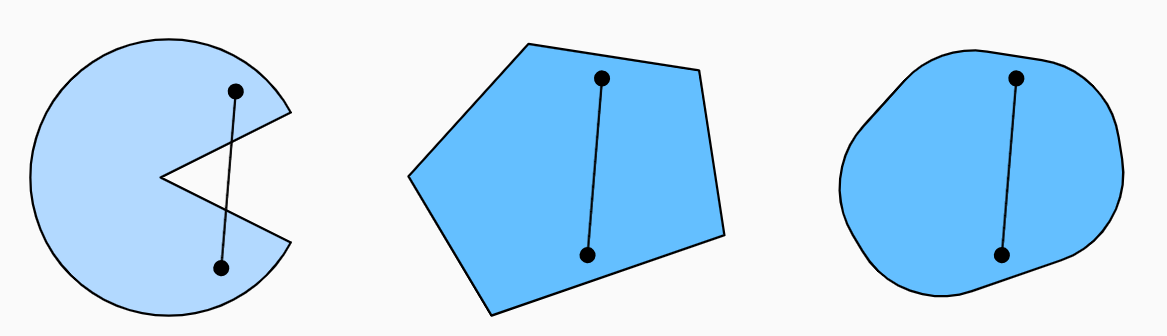
凸集
凸集 (convex set) 是凸性的基础。简单地说,如果对于任何\(a,b\in\mathcal{X}\),连接\(a\)和\(b\)的线段也位于\(\chi\)中,则向量空间中的一个集合\(\chi\)是凸(convex)的。在数学术语上,这意味着对于所有\(\lambda\in[0,1]\),我们得到
\[
\lambda a+(1-\lambda)b\in\mathcal{X}\text{ 当 }a,b\in\mathcal{X}.
\] 
凸函数
定义
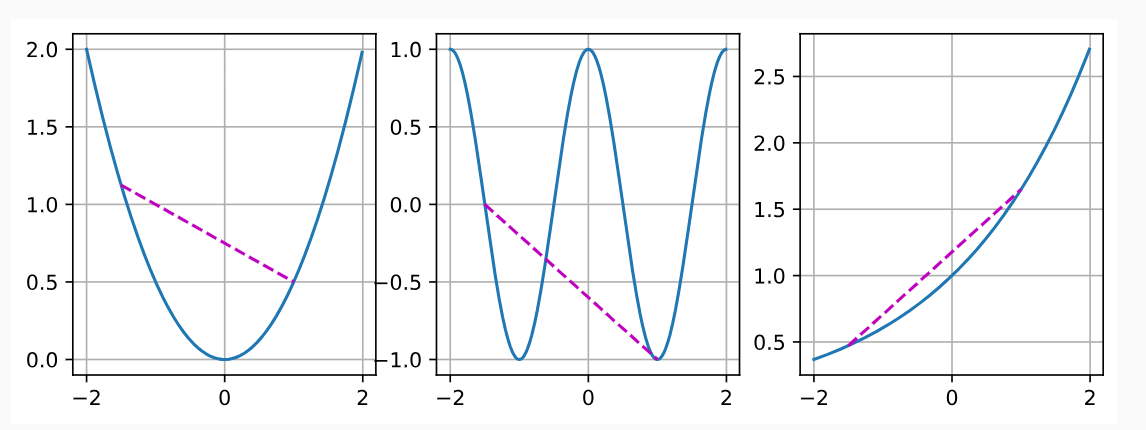
给定一个凸集\(\chi\),如果对于所有\(x,x^{\prime}\in\mathcal{X}\)和所有\(\lambda\in[0,1]\), 函数\(f:\mathcal{X}\to\mathbb{R}\)是凸的,我们可以得到
\[ \lambda f(x)+(1-\lambda)f(x')\geq f(\lambda x+(1-\lambda)x'). \] - 凸函数在定义域上的任意两点之间的割线总在这两点连线的上方或者重合。 - 当一个函数的二阶导数存在且大于0时,函数为凸函数
性质
- 局部最小值是全局最小值
约束优化
问题
最开始,我们有一个目标函数f(x),我们想要找到一个使f(x)最小的x。然而,此时我们还有x要满足的约束条件。这就是以下形式的约束优化 (constrained optimization) 问题:
\[ \begin{array}{c}\mathrm{minimize~}f(\mathbf{x})\\\mathrm{subject~to~}c_i(\mathbf{x})\leq0\text{ for all }i\in\{1,\ldots,N\}.\end{array} \]
\(f\)是目标函数,\(c_i\)是约束函数。
例如第一个约束\(c_1(\mathbf{x})=\|\mathbf{x}\|_2-1\),则参数\(\mathbf{x}\)被限制为单位球。如果第二个约束\(c_2(\mathbf{x})=\mathbf{v}^\top\mathbf{x}+b\),那么这对应于半空间上所有的\(\mathbf{x}\)。同时满足这两个约束等于选择一个球的切片作为约束集。
这样的问题难以直接解决,但物理中的一个类比却可以帮助我们。想象一下一个盒子里的一个球,如果你把盒子倾斜,球会滚到最低点,也就是说,它会找到一个使得它的重力势能最小的位置。同时,它还受到盒子壁的力的限制,不能滚出盒子。
这就是优化问题的动态版本:球(或你的解)被赋予了初始位置和速度,并且随着时间的推移,它在尽可能降低自己的重力势能(也就是目标函数f(x))的同时,还要受到盒子壁力(也就是约束)的限制。
解决
拉格朗日乘数法
为了将这个直观的物理问题转化为数学形式,我们引入了拉格朗日函数L,以及配套的一组拉格朗日乘子α_i。拉格朗日函数是目标函数加上所有约束条件(每个约束前乘以一个拉格朗日乘子)。每一个拉格朗日乘子对应一个约束,它的作用就像一个“弹簧”,当约束被违反的时候,它就会“推”解回到符合条件的地方。_
例如,如果一个解x违反了某个约束(约束条件为\(c_i(x) > 0\)),那么对应的拉格朗日乘子α_i就会增大,从而增加L的值,反过来这就“推动”解x去寻找一个更小的L,也就是说,被“推”回到符合约束的地方。 \[ L(\mathbf{x},\alpha_1,\ldots,\alpha_n)=f(\mathbf{x})+\sum_{i=1}^n\alpha_ic_i(\mathbf{x})\mathrm{~where~}\alpha_i\geq0. \]
- 变量\(\alpha_i\quad(i=1,\ldots,n)\) 是拉格朗日乘数 (Lagrange multipliers) ,它确保约束被正确地执行。
鞍点优化问题,即目标函数在一部分维度上是要进行最大化,在另一部分维度上进行最小化的问题。这种情况在视觉上就像一个马鞍,因此被称为鞍点(有时也被称为最小最大问题)。
在拉格朗日对偶问题中,构造出的拉格朗日函数 \[ L(\mathbf{x},\alpha,\beta)=f(\mathbf{x})+\sum_i\alpha_ig_i(\mathbf{x})+\sum_j\beta_jh_j(\mathbf{x}) \]
- 其中,\(\alpha_i\)是不等式约束,\(\beta_j\)是等式约束
- 当我们考虑\(\alpha\)和\(\beta\)固定,优化变量x时,我们希望最小化\(L(\mathbf{x},\alpha,\beta)\),即在x维度上,\(L\)函数需要被最小化。
- 而当我们考虑\(\mathbf{x}\)固定,优化拉格朗日乘子\(\alpha\)和\(\beta\)时,我们希望最大化\(L(\mathbf{x},\alpha,\beta)\),因为这将强制满足所有约束。
- 综上,即\(L(\mathbf{x},\alpha,\beta)\)在x维度上是要进行最小化,在α和\(\beta\)维度上进行最大化,这正是鞍点问题的特性。所以说拉格朗日对偶问题是一个鞍点优化问题。
举例:
- 假设约束条件为:要求所有\(i\)的\(c_i(\mathbf{x})\leq0\)
- 那么,对于已经满足\(c_i(\mathbf{x})<0\)中任意\(\mathbf{x}\),会选择让\(\alpha_i=0\)。因为如果约束\(c_i(\mathbf{x})<0\)已经满足了,我们就不需要进一步“强制”这个约束条件了,所以对应的拉格朗日乘数\(\alpha_i\)就可以设为0。这是基于KKT (Karush-Kuhn-Tucker) 条件中的互补松弛性原理。
- 但如果这个约束被违反,即\(c_i(\mathbf{x})>0\),那么\(\alpha_ic_i(\mathbf{x})\)的值就会导致拉格朗日函数的值增大,从而“惩罚”违反约束的解(因为\(\alpha_i\)为非负数,\(c_i(\mathbf{x})\)为正数,他们的乘积为正,从而使原要最小化的目标函数的值增大)。最大化\(\alpha_ic_i(\mathbf{x})\)相当于"最大化“其惩罚力度,这样我们可以排除掉所有违反约束条件的解,这就像把违反约束的解的目标函数值“推”到更大的位置。
添加惩罚
投影
如果我们有一个点,我们可以寻找在某个集合中与这个点最接近的点。这个最接近的点就被称为原始点在这个集合上的投影。我们可以把这个投影过程理解为一个修正过程,修正原始点使其满足一定的限定条件。
梯度下降
- 学习率的大小很重要:学习率太大会使模型发散,学习率太小会没有进展。
- 梯度下降会可能陷入局部极小值,而得不到全局最小值。
- 在高维模型中,调整学习率是很复杂的。
- 预处理有助于调节比例,比如针对不同量纲的变量进行标准化,相当于为每个变量选择不同的学习率
- 牛顿法在凸问题中一旦开始正常工作,速度就会快得多。对于非凸问题,不要不作任何调整就使用牛顿法。
随机梯度下降
随机梯度更新
如果使用梯度下降法,则每个自变量迭代的计算代价为\(\mathcal{O}(n)\),它随\(n\)线性增长。因此,当训练数据集较大时,每次迭代的梯度下降计算代价将较高。
随机梯度下降(SGD) 可降低每次迭代时的计算代价。在随机梯度下降的每次迭代中,我们对数据样本随机均匀采样一个索引\(i\),其中\(i\in\{1,\ldots,n\}\),并计算梯度\(\nabla f_i(\mathbf{x})\)以更新\(\mathbf{x}:\) \[ \mathbf{x}\leftarrow\mathbf{x}-\eta\nabla f_i(\mathbf{x}), \] - \(\eta\)是学习率。
因此,每次迭代的计算代价从梯度下降的\(\mathcal{O}(n)\)降至常数\(\mathcal{O}(1)\)。
此外,这里要强调随机梯度\(\nabla f_i(\mathbf{x})\)是对完整梯度\(\nabla f(\mathbf{x})\)的无偏估计,因为 \[ \mathbb{E}_i\nabla f_i(\mathbf{x})=\frac1n\sum_{i=1}^n\nabla f_i(\mathbf{x})=\nabla f(\mathbf{x}). \] 这意味着,平均而言,随机梯度是对梯度的良好估计。
动态学习率
(需要用到再学习)
小批量随机梯度下降
观测单个数据来更新参数,需要执行许多单一矩阵-矢量 (甚至矢量-矢量) 乘法,这耗费相当大,而且对应深度学习框架也要巨大的开销。
也就是说,采用随机梯度下降时,每当我们执行\(\mathbf{w}\gets\mathbf{w}-\eta_t\mathbf{g}_t\),都消耗巨大。其中 \[ \mathbf{g}_t=\partial_\mathbf{w}f(\mathbf{x}_t,\mathbf{w}). \] 我们可以通过将其应用于一个小批量观测值来提高此操作的\(i\)计算效率。也就是说,我们将梯度\(\mathbf{g}_{t}\)替换为一个小批量而不是单个观测值
\[ \mathbf{g}_t=\partial_\mathbf{w}\frac1{|\mathcal{B}_t|}\sum_{i\in\mathcal{B}_t}f(\mathbf{x}_i,\mathbf{w}). \]
- 优良的副作用:
- 由于\(\mathbf{x}_t\)和小批量\(\mathcal{B}_t\)的所有元素都是从训练集中随机抽出的,因此梯度的期望保持不变。
- 此外,方差显著降低。由于小批量梯度由正在被平均计算的\(b:=|\mathcal{B}_t|\)个独立梯度组成,其标准差降低了\(b^{-\frac12}\)。这本身就是一件好事,因为这意味着更新与完整的梯度更接近了。
动量法
泄露平均值
上一节中我们讨论了小批量随机梯度下降作为加速计算的手段。它也有很好的副作用,即平均梯度减小了方差。小批量随机梯度下降可以通过以下方式计算: \[ \mathbf{g}_{t,t-1}=\partial_\mathbf{w}\frac1{|\mathcal{B}_t|}\sum_{i\in\mathcal{B}_t}f(\mathbf{x}_i,\mathbf{w}_{t-1})=\frac1{|\mathcal{B}_t|}\sum_{i\in\mathcal{B}_t}\mathbf{h}_{i,t-1}. \] 为了保持记法简单,在这里我们使用\(\mathbf{h}_{i,t-1}=\partial_{\mathbf{w}}f(\mathbf{x}_i,\mathbf{w}_{t-1})\)作为样本\(i\)的随机梯度下降,使用时间\(t-1\)时更新的权重\(t-1\)。
如果我们能够从方差减少的影响中受益,甚至超过小批量上的梯度平均值,那很不错。
完成这项任务的一种选择是用泄漏平均值 (leaky averaqe) 取代梯度计算: \[ \mathbf{v}_t=\beta\mathbf{v}_{t-1}+\mathbf{g}_{t,t-1} \]
- 其中\(\beta\in(0,1)\)。
- 这有效地将瞬时梯度替换为多个“过去”梯度的平均值。
- \(\mathbf{v}\)被称为动量(momentum), 它累加了过去的梯度。
- 为了更详细地解释,让我们递归地将\(\mathbf{v}_t\)扩展到:
\[ \mathbf{v}_t=\beta^2\mathbf{v}_{t-2}+\beta\mathbf{g}_{t-1,t-2}+\mathbf{g}_{t,t-1}=\ldots,=\sum_{\tau=0}^{t-1}\beta^\tau\mathbf{g}_{t-\tau,t-\tau-1}. \]
- 其中,较大的\(\beta\)相当于长期平均值,而较小的\(\beta\)相对于梯度法只是略有修正。
- 新的梯度替换不再指向特定实例下降最陡的方向,而是指向过去梯度的加权平均值的方向。这使我们能够实现对单批量计算平均值的大部分好处,而不产生实际计算其梯度的代价。
动量法
使用\(\mathbf{v}_t\)而不是梯度\(\mathbf{g}_t\)生成以下更新等式:
\[ \begin{aligned}&\mathbf{v}_t\leftarrow\beta\mathbf{v}_{t-1}+\mathbf{g}_{t,t-1},\\&\mathbf{x}_t\leftarrow\mathbf{x}_{t-1}-\eta_t\mathbf{v}_t.\end{aligned} \]
- \(g_{t,t-1}\)指在时间\(t-1\)的参数值下,时间\(t\)的梯度
动量\(v_t\)实际上是过去所有梯度的一个“加权平均”,可以看做是对历史梯度的“记忆”。每次迭代,我们不仅考虑当前的梯度,也考虑过去的梯度,用它们的加权平均值来指导搜索方向,使得搜索过程更加平滑,减少震荡,从而加快收敛速度。
这也是为什么被称为“动量”的原因,它像物理中的动量一样,赋予了我们的搜索过程惯性,使得搜索方向不会轻易地被当前梯度改变,从而使得搜索过程更加稳定。