GLIP论文理解
GLIP论文理解
GLIP(Grounded Language-Image Pre-training) 是一个可扩展的(generalizable)目标检测模型(其实准确来说应该表述为短语定位模型,本句在这里将"目标检测"和"短语定位"任务混为一谈)
在文章开头先解释一下GLIP论文中用到的一些"黑话"
generalizable(可泛化):侧重于描述模型在不同任务和数据集上的适应性,强调模型学到的特征能够泛化到新的情境。
scalable(可扩展): 关注系统、算法、数据集的可扩展性,确保算法在面对更大规模、更复杂的情况时性能能够保持或提高。在本论文中用到的描述为" scalable and semantic-rich data",侧重于强调数据集的可扩展性,论文通过自训练生成伪标注的方式提高数据集的可扩展性。
language-aware(语言感知的):模型能够理解和处理自然语言。本论文的模型接收文本描述prompt作为输入,自然是language aware的。
semantic-rich(语义丰富的):用于形容数据集包含了丰富的语义信息(包括对物体、场景或其他视觉元素的深层次、有意义的描述,能够捕捉图像中物体之间的关系等)
方法核心
通过将目标检测任务重新表述为视觉-语言任务(也叫短语定位任务),从而统一目标检测和短语定位任务。
如何实现目标检测和短语定位任务的统一?
- 改变训练输入
- 典型的目标检测模型训练时只输入图片,然后模型试图预测图片中目标的类别及边界框,为了使预测结果与ground truth越来越接近,模型不断地学习和调整,逐渐成为一个优秀的好模型。
- 然而,GLIP选择不走寻常路。它舍弃了上述的典型输入(只输入图片),转而向模型输入"图片和对应的文本描述",其中文本描述有两种类型,
- 针对目标检测数据集:一条由所有候选类名构成的合成句子
- 针对短语定位数据集:对图片的自然语言描述
- 改变训练目的
- 典型的目标检测模型是为了使预测结果(分类标签和边界框位置)和ground truth越来越接近
- 而GLIP则是为了识别出句子中的短语和图像中的对象之间的细粒度对应关系
- 改变损失函数(损失函数是由训练目的决定的)
- 用单词-区域对齐得分(word-region alignment scores)取代原先目标检测分类头的对象分类得分(object classification logits)
- 通过region(or box) visual features 和 token(or phrase) language features 的点乘,来计算单词-区域对齐得分
统一这两个任务有什么好处?
- 扩大数据集:训练时可以同时使用这两种任务的数据集
- 训练结果有益于这两种任务(win-win)
- 从检测任务的角度来看,使用定位任务的数据,极大丰富了检测任务的视觉概念池子
- 从定位任务角度来看,使用检测任务的数据,引入了更多边界框标注,有助于训练新的SOTA的定位模型
模型结构
模型结构
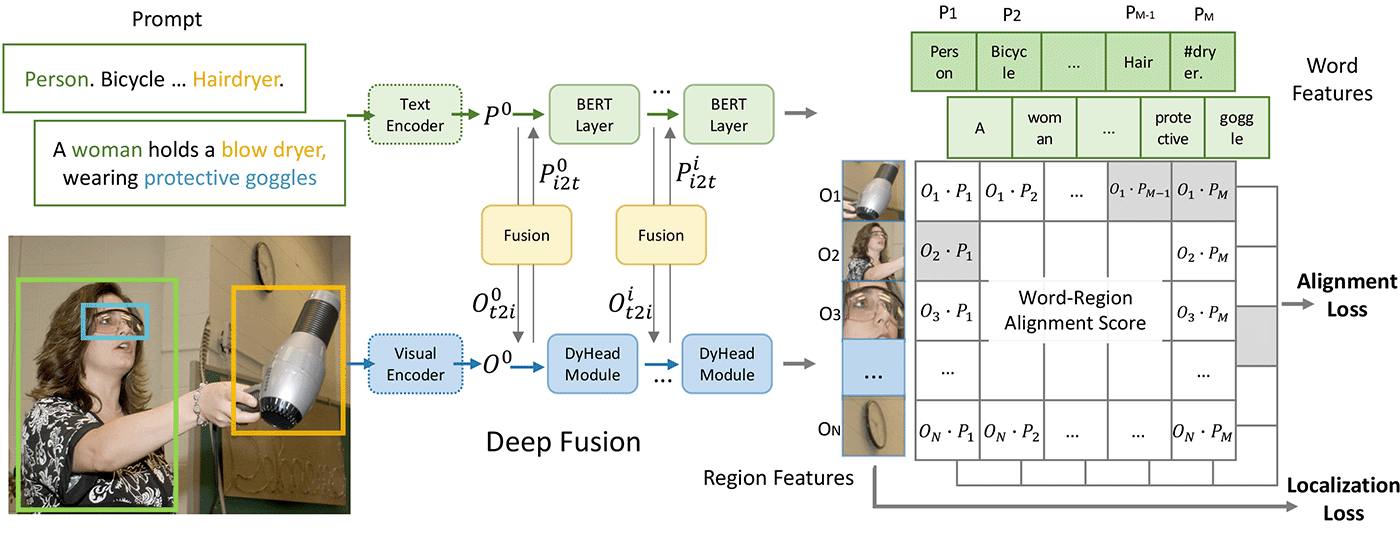
特点
双编码器结构
- 文本编码器
- 视觉编码器
输入
- 图片
- 文本描述
损失
- 对齐损失
- 定位损失
深度跨模态融合:
相比于CLIP只在最后一个层通过点乘来融合视觉和语义信息,GLIP进行了深度跨模态融合,这对于学习高质量、语义感知的视觉表达很关键
训练过程
训练教师模型(train a teacher GLIP on a moderate amount of gold grounding data)
- 模型结构:GLIP
- 训练数据:适量的、人工标注的(gold data)、定位数据集
- 训练结果:获得了一个良好的定位模型
利用教师模型生成伪标注边界框(generate grounding boxes for massive image-text-paired data)
- 做法:利用教师模型在massive image-text-paired data上做预测,预测与文本中的短语对应的图像中的目标的边界框
- 源数据:massive image-text-paired data(互联网爬取的、大量的、图像-文本对、没有目标边界框信息)
- 处理后数据:图像-文本-目标边界框,形成了一个新的、更大的、定位数据集
- 好处:
- 过去为了训练一个更好的目标检测模型,通常会直接扩展目标检测数据集,但是再怎么扩展,模型依旧无法预测超出"训练数据涉及到的视觉概念库"中的视觉概念
- 然而本文通过"互联网搜集大量图像-文本对" + "教师模型生成伪标注边界框"的方式,获得了一个语义丰富的定位数据集,从而极大地扩展了视觉概念,改善了下游任务的运行效果(尤其在一些罕见类别上)
预训练学生模型
- 数据集:2中大量的伪标注数据集+1中适量的人工标注数据集,构成了一个语义丰富的新数据集
- 模型结构:GLIP
- 训练结果:获得了一个语义丰富的目标检测模型
微调上述学生模型,实现知识迁移
法一:直接在预测时输入特定任务的文本描述prompt(如增加的新类别、对属性特征的进一步描述等),此时不需要额外标注数据,GLIP可以直接进行领域迁移

法二:当有特定领域的标注数据时,不需要微调整个模型,我们可以在保持模型参数不变的情况下,只微调特定领域的提示嵌入向量(prompt embedding)。通过提示学习,GLIP模型可以适应各种下游任务,减少了微调和部署的花费。(提示学习可以参考论文MaPLe: Multi-modal Prompt Learning)