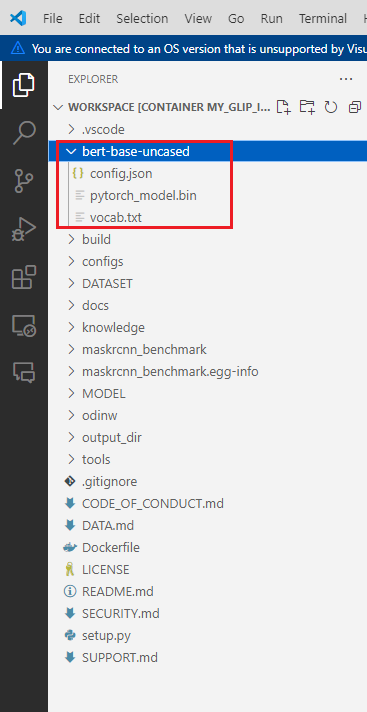
MaxRetryError("HTTPSConnectionPool(host='huggingface.co', port=443):
Max retries exceeded with url:
/bert-base-uncased/resolve/main/config.json (Caused by
ConnectTimeoutError('Connection to huggingface.co timed out. ),
'(Request ID: 7b33f5be-46a9-40b5-a198-d5ff7ef25c7c)')' thrown while
requesting HEAD
https://huggingface.co/bert-base-uncased/resolve/main/config.json
Traceback (most recent call last): File "tools/train_net.py", line
260, in main() File "tools/train_net.py", line 256, in main
use_tensorboard=args.use_tensorboard) File "tools/train_net.py", line
37, in train model = build_detection_model(cfg) File
"/workspace/maskrcnn_benchmark/modeling/detector/init.py",
line 11, in build_detection_model return meta_arch(cfg) File
"/workspace/maskrcnn_benchmark/modeling/detector/generalized_vl_rcnn.py",
line 96, in init self.language_backbone =
build_language_backbone(cfg) File
"/workspace/maskrcnn_benchmark/modeling/language_backbone/backbone.py",
line 45, in build_backbone return registry.LANGUAGE_BACKBONEScfg.MODEL.LANGUAGE_BACKBONE.MODEL_TYPE File
"/workspace/maskrcnn_benchmark/modeling/language_backbone/backbone.py",
line 14, in build_bert_backbone body = bert_model.BertEncoder(cfg) File
"/workspace/maskrcnn_benchmark/modeling/language_backbone/bert_model.py",
line 18, in init config =
BertConfig.from_pretrained(self.bert_name)
File
"/opt/conda/lib/python3.7/site-packages/transformers/configuration_utils.py",
line 547, in from_pretrained config_dict, kwargs =
cls.get_config_dict(pretrained_model_name_or_path, kwargs) File
"/opt/conda/lib/python3.7/site-packages/transformers/configuration_utils.py",
line 574, in get_config_dict config_dict, kwargs =
cls._get_config_dict(pretrained_model_name_or_path, kwargs) File
"/opt/conda/lib/python3.7/site-packages/transformers/configuration_utils.py",
line 641, in _get_config_dict _commit_hash=commit_hash, File
"/opt/conda/lib/python3.7/site-packages/transformers/utils/hub.py", line
453, in cached_file f"We couldn't connect to
'{HUGGINGFACE_CO_RESOLVE_ENDPOINT}' to load this file, couldn't find it
in the"
OSError: We couldn't connect to 'https://huggingface.co' to
load this file, couldn't find it in the cached files and it looks like
bert-base-uncased is not the path to a directory containing a file named
config.json.
===总之就是在说:我们需要从huggingface官网下载这个config.json文件到本地
Checkout your internet connection or see how to run the library in
offline mode at
'https://huggingface.co/docs/transformers/installation#offline-mode'.
错误信息:DataLoader worker (pid 53617) is killed by signal: Bus
error. It is possible that dataloader's workers are out of shared
memory. Please try to raise your shared memory limit.
RuntimeError: DataLoader worker (pid 53617) is killed by signal: Bus
error. It is possible that dataloader's workers are out of shared
memory. Please try to raise your shared memory limit.